
Processing podcasts part 1
Async workflows, dealing with large files, vector embeddings, ChatGPT, MySQL full-text indices - Processing podcasts

Introduction
Well, I listen to lots of podcasts. Mainly while driving. And I really like driving, so I want to listen to good episodes. I want three features desperately:
Selecting an episode that I’ve already listened to and telling my phone “hey, give me three podcast episodes that discuss very similar topics”
Asking questions about a particular episode. For example, I hate that when they recommend something (a website, a tool, anything) and I forget it, and the episode is 52 minutes long. After I listen to it, I want to be able to ask a question such as “give me every website they mentioned.”
Being able to search keywords in the content of a whole episode. For example, typing “stihl chainsaw“ and then seeing every episode where they talk about this topic. Well, it’s an existing feature, but it’s interesting so we’re going to build it.
I don’t know if it’s just me but I really miss those two features.
Let’s pretend we’re building a podcast platform and want to add those features. All of these require the text version of the episode so the app can search it effectively. So let’s start with that.
Transcribing an episode
There are multiple speech-to-text APIs out there. In this post, I’m going to use OpenAI since it can solve other problems as well.
In PHP, the openai-php/client SDK can be used to interact with the OpenAI API.
There’s an /audio/transcriptions API and the whisper-1 that can be used for speech-to-text.
The OpenAiService class implements simple methods to communicate with the API:
namespace App\Services;
class OpenAiService
{
private Client $client;
public function __construct(private string $apiKey)
{
$this->client = OpenAI::client($this->apiKey);
}
public function transcribe(string $filePath): ?string
{
$response = $this->client->audio()->transcribe([
'model' => 'whisper-1',
'file' => fopen($filePath, 'r'),
]);
return $response->text;
}
}The transcribe API accepts an audio file and the model. That’s it. Now we have the whole script of a podcast episode. Of course, transcribing takes time so let’s dispatch a job.
This controller is responsible for uploading a new episode to a podcast:
namespace App\Http\Controllers;
class PodcastEpisodeController extends Controller
{
public function store(Request $request, Podcast $podcast)
{
/** @var Episode $episode */
$episode = Episode::create([
'podcast_id' => $podcast->id,
'audio_file_path' => FileService::upload($request->file),
'title' => $request->title,
]);
TranscribeEpisodeJob::dispatch($episode);
return $episode;
}
}Of course, the job itself is pretty simple. It just calls the service:
namespace App\Jobs;
class TranscribeEpisodeJob implements ShouldQueue
{
use Queueable;
public function __construct(private Episode $episode)
{
}
public function handle(OpenAiService $openAi): void
{
$this->episode->content = $openAi
->transcribe($this->episode->audio_file_path);
$this->episode->save();
}
}If you now upload a new MP3 file you have the text version of it.
Summarizing an episode
The next thing the app needs to do is summarize an episode. It’s not necessary for the features but it’s a must-have in every podcast platform. Fortunately, it’s pretty easy with ChatGPT:
public function summarize(string $text): ?string
{
$response = $this->client->chat()->create([
'model' => 'gpt-4o',
'messages' => [
[
'role' => 'user',
'content' => 'Summarize the following text in 5-8 sentences. Text: "' . $text . '"'
],
],
]);
if (empty($response->choices)) {
return null;
}
return $response->choices[0]->message->content;
}This gives us a 5-8 sentence summary of the whole episode. For this task, the standard gpt model can be used. This is the same everybody uses on chat.openai.com.
Now the application has the full transcript and the summary of an episode. This is enough to search for keywords in the text. However, it’s not quite enough to compare episodes and recommend similar ones. In order to do this we need embeddings.
Creating embeddings
The way ChatGPT works is that it represents words (or parts of words, called tokens) as vectors.
To simplify this, let’s say we want to represent foods on a 2-dimensional coordinate system where:
The y-axis is the awesomeness
The x-axis is the amount of calories
Given the fact that the most awesome foods in the world are:
Gulyás (also known as Goulash)
Langos (Germans call it Fladen and oh boy, they like it)
Wiener schnitzel (we call it Bécsi szelet and oh boy, we like it)
Pizza
Hamburger
Honorable mentions are Souvlaki, Gyros, and Bolognese spaghetti.
So let’s put them on a coordinate system based on their awesomeness and the amount of calories:
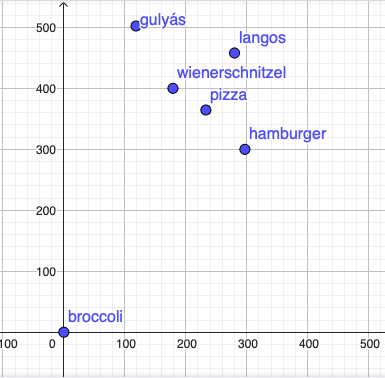
Given these two properties, if you want the best of the best, you can draw a circle and get “similar” foods (similar in only these two attributes):
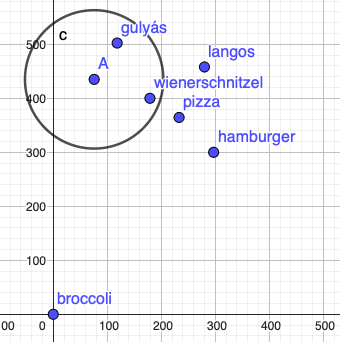
It’s easy to see that similar foods are closer to each other. Based on these two properties you’ll never get to brocolli if you want something like Goulash.
ChatGPT does the same thing with words. It converts words into fixed-length numerical vectors. But instead of two, it uses hundreds of dimensions. Words are placed in this crazy vector based on their semantic similarity.
So similar words are closer and dissimilar words are further from each other. Obviously, this is an oversimplification (since I don’t understand it), but this is the basic idea. This is the fundamental of their chat.
We can use this technique to represent episodes’ contents as vectors and use OpenAI to compare two of them.
Embeddings are represented as pretty huge arrays of float numbers, for example:
[-0.004509021, -0.029033067, -0.018577553, 0.011880094, ...]Each number represents the position of a coordinate but in reality, it’s a very big array:

This is the embedding of a 247-word text.
Fortunately, creating the embedding of a text is simple:
public function createEmbeddings(string $text): array
{
$response = $this->client->embeddings()->create([
'model' => 'text-embedding-ada-002',
'input' => $text,
]);
return $response->embeddings[0]->embedding;
}They offer specialized models for embeddings such as “text-embedding-ada-002”
Now the three preparation tasks are done:
Transcribing the episode
Summarizing it
Creating the embeddings
All of them take a long time to complete so they are queue jobs. However, summarizing and creating the embeddings depend on transcribing since it provides the episode’s content.
The app needs to run the jobs in this order:
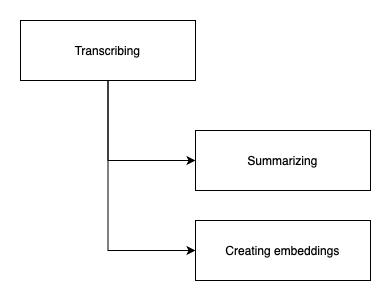
First, transcribing needs to finish and then the other two can run in parallel. They don’t depend on each other. So the controller looks like this:
class PodcastEpisodeController extends Controller
{
public function store(Request $request, Podcast $podcast)
{
/** @var Episode $episode */
$episode = Episode::create([
'podcast_id' => $podcast->id,
'audio_file_path' => FileService::upload($request->file),
'title' => $request->title,
]);
Bus::batch([
[
new TranscribeEpisodeJob($episode),
],
[
new SummarizeEpisodeJob($episode->refresh()),
new CreateEmbeddingsForEpisodeJob($episode->refresh()),
],
])
->dispatch();
return $episode;
}
}The Bus::batch() part reads as follows:
I want to dispatch a batch of jobs
But in order
First, transcribing on its own
Then the other two after transcribing finished
Now that the app has everything let’s start with searching in the content.
Searching in the content
Searching in the episode’s content is pretty easy. However, the content can be pretty large. Let’s estimate how large.
The average speaking speed of a normal person is 125 to 150 words per minute. Let’s call it 150.
The average podcast episode I listen to is about 40-60 minutes. Let’s call it 1 hour.
One hour contains about 7,500 to 9,000 words. If there are two people my experience is that the episode is a bit faster, so let’s call the average 10,000 since most podcasts have two hosts.
The average length of an English word is 4.7 characters. Let’s call it 5.
10,000 words * 5 characters = 50,000 characters
So an average podcast episode is 50,000 written characters.
In MySQL, a TEXT column can store 65,535 characters (2^16). This is not enough if the average estimate is 50k chars. We need a MEDIUMTEXT that can hold 16MB of data or 16 million characters. That’s more than enough.
Larger columns, indices, and LIKE %
MEDIUMTEXT columns come with one small problem. You cannot create good indices on them.
They are simply too large. An index is a B+ Tree and leaf nodes are supposed to store a disk page. A page is usually 4KB or 16KB (run getconf PAGE_SIZE to find out on a Mac or Linux). If I understand it correctly, this is the reason.
