
But how memory actually works?
Exploring the stack, the heap, garbage collection, passing by reference vs passing by value

Introduction
I truly believe that every software engineer should have a good understanding of how memory and process management work.
Stack
There are two kinds of memory our programs can use: the stack and the heap.
The stack is a short-term memory for functions. Each thread has its own stack. It’s a small piece of memory. For example, in Go 1.2, the default stack size is 8KB. Function calls and local variables live in this 8KB space.
Consider the following example:
package main
func main() {
n := 10
squared := square(n)
fmt.Println(squared)
}
func square(x int) int {
return x*x
}When you start the program and the main() function starts running this is what the stack looks like:

The yellow rectangle represents the entire 8KB stack for the main thread. Whenever a function is called a new frame is created for it. The green box is the stack frame for function main. Local variables live in that frame.
This is why we have function scopes in most languages. When a function returns, its local variables cannot be accessed anymore. It’s because the stack frame is cleared. Some languages (such as Go) don’t actually remove the stack frame after a function returns but it marks it as invalid and it cannot be accessed anymore. The result is the same.
When the square() function is called the stack looks like this:

A new frame is pushed onto the stack. This is for square() and it contains its local variable, x. I marked main’s stack frame as red because it is out of the scope at the moment.
When square() returns, the frame is popped from the stack (or marked as invalid):

Finally, Println() is called:

After it is finished, the main() function returns and the stack is empty.
When you have an error in your program and it throws an exception, you see a call stack. That stack trace is exactly what we’re talking about here.
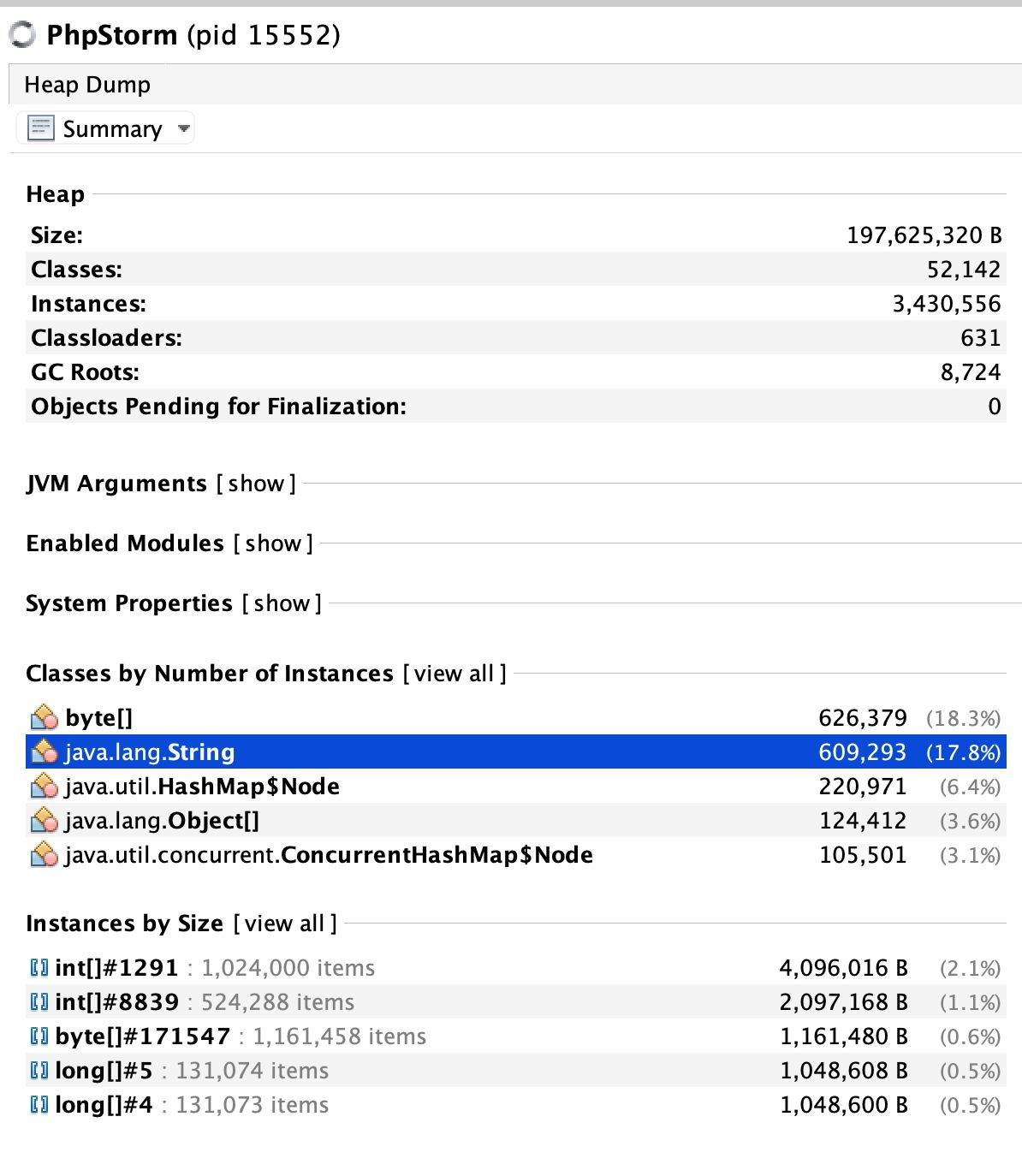
The stack is small and it’s primarily for short-lived variables. What happens with bigger objects? And what happens if your function needs 8MB of memory instead of 8KB? For example, when I ran PhpStorm, it loaded 600k strings, 600k byte arrays, and 100k objects into memory:
Heap
The heap is a much larger and less organized part of the memory. Each program has its own heap space. While the stack follows a LIFO (last in first out) order, the heap can be accessed randomly. Because of that, it’s slower but much larger as well. For example, on my system, Java has a 268MB initial heap size:

Typically, objects and arrays are stored in the heap since they are larger than primitives. Let’s say you have an array with 1,000 integers. It’s already 8KB. Now imagine 1,000 User objects.
Consider this example:
function main() {
$user = new User("John Doe");
$str = "hello"
greetUser($user, $str);
}
function greetUser(User $user, string $message) {
echo $message . ' ' . $user->name;
}The `$user` variable in the main() function is actually a pointer. Since PHP doesn’t allow us to use pointers we often call them as references. In this article, I’ll use these terms interchangeably. So in the stack frame `$user` doesn’t actually hold the User object but only a memory address. And that address points to a value in the heap:

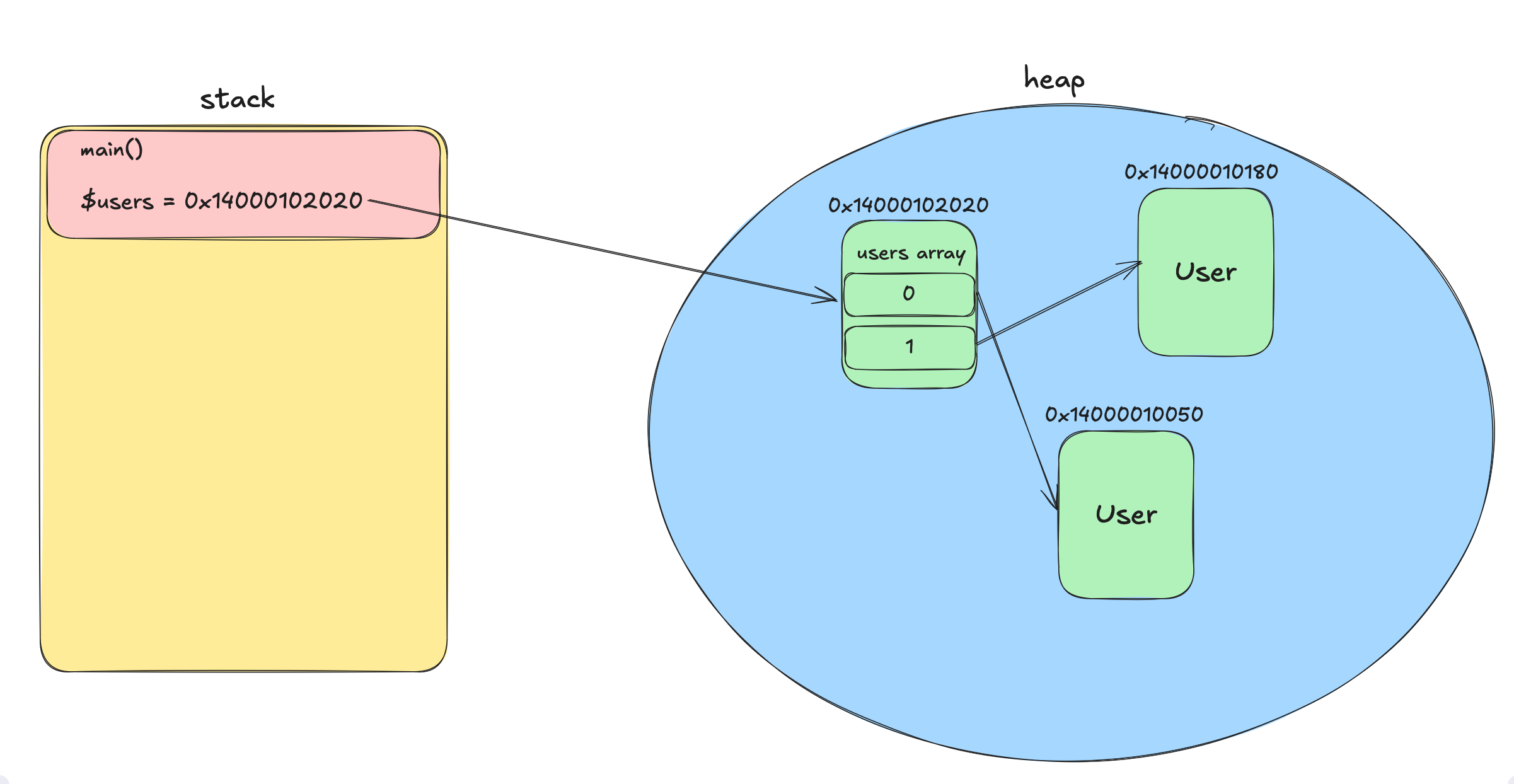
Of course, variables inside the heap can also point to other variables. Imagine an array of Users:
function main() {
$users = [
new User("John Doe"),
new User("Jane Doe"),
];
}
What happens when the function returns and the stack frame is deleted? The variable `$users` is deleted. But it’s not the actual array. It’s just a reference, a pointer:

The actual data in the heap is not deleted just because the `$users` reference is gone. It only deletes the pointer. But in this specific case, the `$users` array is not used anymore. It’s not referenced by any variable in the stack. It’s basically garbage. How does it get removed from the heap?
Garbage collection
Garbage collection removes the two User objects and the array from the heap. Managed languages such as PHP, Go, Java has garbage collection. It means that we don’t have to manually free up memory. The language does it for us.
PHP uses a common technique called reference counting, Each variable you define is stored as a zval. It’s a struct that stores the value and lots of meta data such as type information, etc. It looks like this:
struct _zval_struct {
zend_value value;
union {
uint32_t type_info;
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar type,
zend_uchar type_flags,
union {
uint16_t extra;
} u)
} v;
} u1;
// ...
};The first field is a zend_value which is a union:
typedef union _zend_value {
zend_long lval; // For IS_LONG
double dval; // For IS_DOUBLE
zend_refcounted *counted;
zend_string *str; // For IS_STRING
zend_array *arr; // For IS_ARRAY
zend_object *obj; // For IS_OBJECT
zend_resource *res; // For IS_RESOURCE
zend_reference *ref; // For IS_REFERENCE
zend_ast_ref *ast; // For IS_CONSTANT_AST (special)
zval *zv; // For IS_INDIRECT (special)
// ...
} zend_value;I marked the 3rd field with bold letters. It’s a zend_refcounted field. It’s another struct:
typedef struct _zend_refcounted_h {
uint32_t refcount;
union {
uint32_t type_info;
} u;
} zend_refcounted_h;And there’s the refcount field. It’s an unsigned integer that holds the number of references that point to this specific variable.
It works like this:
function main() {
// refcount = 1
$user = new User();
// refcount 2
$user1 = $user;
// refcount = 1
unset($user1);
// refcount = 0
return;
}As we discussed earlier, `$user` is just a pointer so when we do `$user1 = $user` you can imagine it like this:
$user = 0x14000102020;
$user1 = 0x14000102020;It just copies the memory address of the User object. refcount is increased since now there are two variables in the stack that points to the User object located at 0x14000102020.
unset is an interesting function. It does the following things:
Decreases the refcount of the variable by one
Removes the variable from the symbol table
If the variable is local, it is removed completely
In the example above, the variable `$user1` is no longer usable after the unset(), and the refcount for the User object is decreased by one.
When the function returns, `$user` is removed as well, so the refcount is decreased by one again. Now it reaches zero.
At this point, the User object located at 0x14000102020 is eligible for garbage collection. The next time the garbage collector runs the value will be removed from memory, and the memory address will be marked as “usable” again.
Garbage collection has two important properties:
It’s safe
But it’s slow
It’s safe because we don’t need to worry about freeing up memory after a variable is no longer in use. Memory leaks are not that common (unless, for some weird reason you use JavaScript on the backend. just stop it please).
It’s slow because garbage collection takes time to run. It’s a complicated algorithm that follows the links between references and finds unused memory addresses. Take another look at PhpStorm’s numbers:

There are 3.4 million variables in the heap. The overall size is 197MB. Imagine a graph with 3.4 edges and an algorithm that traverses it.
Each language implements garbage collection differently. If I’m not mistaken, in PHP, there are parts of the algorithm that block the execution of our code. Fortunately, PHP is a toilet and starts with a fresh state at every request. Generally speaking, memory or memory leaks is not the main concern of a typical PHP API. The Go garbage collector is quite advanced and runs concurrently so it doesn’t block the main thread.
There are unmanaged languages such as C, C++, Rust, or Zig. In these languages, you have to manage memory manually. C is considered unsafe because you have to free the memory yourself, it has no bounds checking, it allows null pointer dereference, dangling pointers, etc. On the other hand, Rust is considered a safe language because it offers solutions to these problems. Zig is in between these two.
By the way, I want to learn one of those languages and potentially write a few posts about it.
(Please don’t forget that I always put my favorite choice first. Thank you!)
Here is a small C example that shows the "unmanaged nature” of it:
#include <stdio.h>
#include <stdlib.h>
int main() {
int *xs = (int*)malloc(3 * sizeof(int));
if (xs == NULL) {
printf("malloc failed\n");
return 1;
}
xs[0] = 1;
xs[1] = 2;
xs[2] = 3;
printf("%d", xs[0]);
free(xs);
xs = NULL;
return 0;
}malloc is short for “memory allocation.” As you can see, we have to allocate the right amount of memory and free it after the variable is no longer needed. Freeing memory is very easy to forget and it’s the root cause of memory leaks. And don’t forget that these languages are not designed in a “request-response” fashion like PHP. These languages are most commonly used in long-running processes, such as nginx. It runs 24/7. Imagine if an nginx developer forgets to call free after handling an incoming request of yours. It might eat up all of your memory over time and crash your server (or at least the nginx process). Each incoming request will allocate X bytes of memory that is never going to be cleared.
Of course, on the other hand, C is superfast partly because it has no garbage collection. You can write the Linux kernel in it that powers the entire internet.
Each language works differently. For example, Go uses a mark-and-sweep garbage collector while Java has a generational algorithm.
Passing by reference/value
Every language has to make a decision that is derived from the stack vs heap situation. Are variables passed to function by reference or value?
Passing by value means that the compiler copies the value of the variable and passes it to the function.
Passing by reference means that the pointer (the memory address of the actual value) is passed to the function.
Let’s look at the properties of these two techniques.
Passing by value
It’s safer because if a function modifies its argument it only has effect in that scope. The variable is not changed in the caller function.
On the other hand, it’s not suitable for modifying the original data in the caller if that’s what you need in a specific case.
It wastes memory since it makes a copy of every function argument.
Passing by reference
It’s unsafe because if a function modifies its argument it has effect outside of its scope. The variable is changed in the caller function as well.
On the other hand, it’s suitable for modifying the original data in the caller if that’s what you need in a specific case.
It uses less memory since it passes pointers (integers) as function argument.
As you can see one’s advantage is the other one’s disadvantage. This is why lots of languages use them both:
Primitive variables are passed by values.
Complex data structures are passed by reference.
This is how PHP works. Everything is passed by value except objects. They are passed by reference.
The array remains unchanged in function main():
main();
function main() {
$xs = [1,2,3];
append($xs, 4);
// [1,2,3]
var_dump($xs);
}
function append(array $xs, int $value): void {
$xs[] = 4;
}But if we do the same with an object it will change in function main() as well:
main();
function main() {
$user = new User("john");
updateName($user, "jane");
// "jane"
echo $user->name;
}
function updateName(User $user, string $name) {
$user->name = $name;
}
class User
{
public string $name;
public function __construct(string $name)
{
$this->name = $name;
}
}The program outputs “jane” since the User object is passed by reference to the updateName() function.
Each language works a bit different. For example, struct are passed by value in Go:
package main
import "fmt"
type User struct {
name string
}
func main() {
u := User{
name: "john",
}
updateName(u, "jane")
// "john"
fmt.Println(u.name)
}
func updateName(user User, name string) {
user.name = name
}This will output “john” because the struct is passed by value. Go does this because it has pointers. In other words, you can pass by reference any type if you pass a pointer:
package main
import "fmt"
type User struct {
name string
}
func main() {
u := User{
name: "john",
}
updateName(&u, "jane")
// "jane"
fmt.Println(u.name)
}
func updateName(user *User, name string) {
user.name = name
}This example will output “jane”. The original user instance is changed as well since we passed a pointer. As we know, a pointer holds a memory address so updateName() has access to the original variable.
Learned alot from this article.
Amazing article 👏🏼. Hope you explain with c language or java 🙏🏼