
Building a load balancer in Go part 1
Learning Golang by building an HTTP load balancer

Introduction
I believe in two things:
If you want to be a better software engineer you should step out of your comfort zone and build things you don’t normally make. You should understand some lower-level concepts even if you work on very high-level web applications.
If you want to learn a new language, stop being fancy about it. Don’t waste your time building CRUD APIs. Don’t build a freaking todo app. Don’t try how you can connect to a MySQL database.
Instead of a CRUD API, you can build a network protocol. Instead of connecting to a MySQL database, you can build your own database.
When you build a CRUD API you won’t learn anything new, You won’t learn anything useful. You’ll just learn a new syntax. Which you’ll forget after 6 days. Now imagine if you build a database storage engine that can create tables, insert and select records in an efficient way. How would you store the data? Would you store each row as a new line in a file? When you want to select a given ID would you read the file line by line until you have the right row? But what happens in a table with 10,000,000 rows? What if you need to sort the results and the table is 5GB large but the server has only 4GB of RAM? These are the questions that will make you a better software engineer. Questions like “Should I return 200 or 201 from the POST /todo API” won’t make too much difference.
In this newsletter, we’re going to learn Go by building:
A load balancer (easy)
A Redis-like key-value store (mid if it’s not distributed)
A database storage engine (hard if you only build certain features. Impossible if you want to go deeper)
A programming language with a compiler (very hard)
(Sorry for the kind of “spicy” introduction. I just watched a Jonathan Blow video.)
Announcement

I’m working on a new project called ReelCode. It’s going to be a coding platform such as LeetCode but with real-world problems. You can learn underlying computer science topics while solving real-world challenges. Supported by high quality descriptions and tutorials.
Data structures
The load balancer is going to be quite simple with the following features:
Reading a config file with a port and target servers
Listening to a port
Forwarding requests to target servers using round-robin
Running health checks to make sure that each server is available
Using connection pools to be more efficient
If you don’t have too much experience with load balancers the following post is a good introduction:

To build the main feature (forwarding requests to servers) we need at least two objects:
Server
LoadBalancer
The server contains a URL and the load balancer contains an array of servers.
In Go, there are no objects or classes. There are structs (just like in C):
type Server struct {
URL string
}(Later, I’m going to add more properties)
It looks like a class with a property. It’s very similar, however, there are some differences: Golang doesn’t have OOP features. Meaning:
No inheritance
No constructors
Only public and private visibility
No methods
Implicit interfaces (there’s no implements keyword but you can implement interfaces)
No
this
I know, I know. It sounds disappointing. But ask yourself the question: if Go was a shitty language that didn’t solve these problems would Docker, docker-compose, Kubernetes, Terraform, Prometheus, GitHub CLI, esbuild, or Vitess use it?
These projects are no jokes. For example, the Kubernetes repo contains 125,000 commits and 418,129 lines of code maintained by ~3,700 people. 97% of the code base is written in Go. The remaining 3% is shell scripts.
Golang offers a solution to all of these problems.
The next struct we need is the LoadBalancer:
type LoadBalancer struct {
Servers []*Server
idx int
}It contains an array of servers. To be more precise, an array of pointers. Go has pointers. A pointer is a simple variable that contains a memory address. That memory address contains the real value. As simple as that. It’s a reference to a variable. I won’t go into the details you can read a lot about this topic if you’re interested.
It also contains an integer index. Our load balancer will use a round-robin algorithm and idx will store the index of the current server where it needs to forward the request.
If you take a look at the struct again, you can see that Servers starts with a capital letter while idx is all lowercase. This is visibility control in Go:
Servers is a public field since it’s capitalized
idx is private since it starts with a lowercase
Later, both of them are going to be private, but for now, it’s easier if Servers is public.
Round-robin
Round-robin is the simplest algorithm:
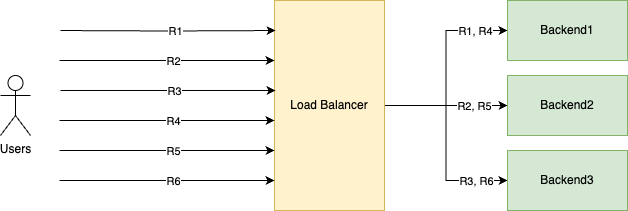
As you can see, requests go through the servers in a "circular order:"
R1 gets handled by Backend1
R2 gets handled by Backend2
R3 gets handled by Backend3
And then it starts over
R4 gets handled by Backend1
R5 gets handled by Backend2
R6 gets handled by Backend3
We need a function that returns the next server. When the first request comes in it should return backend1, when R2 comes in it should return backend2, and so on:
func (lb *LoadBalancer) NextServer() *Server {
server := lb.servers[lb.idx]
lb.idx = (lb.idx + 1) % len(lb.servers)
return server
}As I said, idx contains the current server index. Initially, it is 0. Using idx the function can grab the appropriate server.
After that, it needs to increment the index without overflow. The easiest way is to use the modulo operator. Let’s say we have three servers:
idx = 0
(0 + 1) % 3 = 1
idx = 1
(1 + 1) % 3 = 2
idx = 2
(2 + 1) % 3 = 0It returns the next index without overflow.
That’s it! We implemented the round-robin algorithm.
Now let’s talk about this part:
func (lb *LoadBalancer) NextServer() *Server {}This is called a function receiver. It’s basically, the Go-way of writing a method. The NextServer function can be accessed on a LoadBalancer instance.
A standard function looks like this:
func foo() {}A function receiver has an extra “parameter” between func and the function’s name:
func (lb *LoadBalancer) NextServer()Under the hood, it’s just syntactic sugar. The compiled code looks something like this:
func NextServer(lb *LoadBalancer)lb becomes the first argument to the function. Yeah, that’s it. This is why Go doesn’t have this. This is why lb can be used as a normal argument:
func NextServer(lb *LoadBalancer) *Server {
server := lb.servers[lb.idx]
lb.idx = (lb.idx + 1) % len(lb.servers)
return server
}We’re basically writing procedural code with some syntactic sugar:
func (lb *LoadBalancer) NextServer() *Server {
server := lb.servers[lb.idx]
lb.idx = (lb.idx + 1) % len(lb.servers)
return server
}Writing procedural code might sound lame. Do you know what other software is written in a procedural fashion? Unix. Linux. PostgreSQL. Git. Redis. Python. Nginx. PHP, Doom. Pretty stable stuff, right? The multi-million-line Linux kernel works without inheritance.
Forwarding requests
NextServer() returns the next server we should forward a request. Now, let’s implement the ForwardRequest() function:
import "net/url"
func (lb *LoadBalancer) ForwardRequest(server *Server, uri string) *http.Response {
fmt.Printf("Forwarding request to: %s\n", server.url)
u := url2.Parse(server.url)
fullUrl := url.ResolveReference(&url2.URL{Path: uri})
res := http.Get(fullUrl.String())
return res
}Please, don’t worry about the Go-specific stuff for now. First, understand the algorithm:
When forwarding a request we have the target server (provided by NextServer()) and the URI (provided by the client).
The function concatenates these two strings by:
u := url.Parse(server.url)
fullUrl := u.ResolveReference(&url.URL{Path: uri})url refers to the 1st party URL package imported as “net/url“. You can think about url as a class, and Parse() as a method for now.
We have the URL now, so the only remaining step is to actually send a request to that URL:
http.Get(fullUrl.String())http is another 1st party package imported as net/http. For now, we’re only working with GET methods.
There’s another thing Golang doesn’t have: Exceptions
It’s an “errors as values” language. When something goes wrong in a function it returns an error object. For example:
func Write(file *os.File, content string) error {
err := file.Write(content)
if err != nil {
return err
}
}Instead of throwing an exception it just returns an error object that you can handle at any level. For example, inside the Write() function, or in the function that calls Write, etc. Just like you can do with Exceptions.
But what happens when the function has a return value and it can also return an error? In this case, the function has two return values. Or to be more precise, it returns a tuple:
func Read(file *os.File) (string, error) {
data := make([]byte, 100)
_, err := file.Read(data)
if err != nil {
return "", err
}
return string(data), nil
}If file.Read() returns an error then our Read function returns an empty string and an error object. Otherwise, it returns a string and a nil (which is null).
At first, it seems pretty annoying but you can do everything with errors that you can do with Exceptions. They use try-catch blocks while errors use if statements. They both make the code a bit more complicated.
With error handling, ForwardRequest looks like this:
func (lb *LoadBalancer) ForwardRequest(server *Server, uri string) (*http.Response, error) {
fmt.Printf("Forwarding request to: %s\n", server.url)
client := lb.cp.Pop(server.url)
defer lb.cp.Push(server.url, client)
u, err := url.Parse(server.url)
if err != nil {
return nil, err
}
fullUrl := u.ResolveReference(&url.URL{Path: uri})
res, err := client.Get(fullUrl.String())
if err != nil {
return nil, err
}
return res, nil
}Instead of a single response, the function returns a tuple of (*http.Response, error). Whenever something can go wrong (parsing a URL, sending an HTTP request) errors need to be handled.
Serving incoming requests
The next step is to start listening on an HTTP port and accepting incoming requests. To do that, we need a main package and a main function. Later we’re going to talk about packages in greater detail. For now, you can imagine them as namespaces in a PHP application.
package main
import "net/http"
func main() {
servers := []*loadbalancer.Server{
&loadbalancer.Server{
URL: "http://127.0.0.1:8000",
},
&loadbalancer.Server{
URL: "http://127.0.0.1:8001",
},
}
lb := &NewLoadBalancer{
Servers: servers,
)
err = http.ListenAndServe(":8080", lb)
if err != nil {
panic(err)
}
}The first part creates an array of Server pointers. There’s no new keyword in Go. There’s new() function but it is rarely used. The syntax for creating a new struct is this:
server := Server{
URL: "http://127.0.0.1:8000"
}If you want a pointer, you add the “address of” operator:
server := &Server{
URL: "http://127.0.0.1:8000"
}To initialize an array with values:
names := []string{"John", "Joe", "Jim"}So the following part creates a new array of Server pointers:
servers := []*loadbalancer.Server{
&loadbalancer.Server{
URL: "http://127.0.0.1:8000",
},
&loadbalancer.Server{
URL: "http://127.0.0.1:8001",
},
}loadbalancer.Server is similar to a fully-qualified class name. It contains the package name (loadbalancer) and the struct name as well. We’re going to talk more about this later.
After creating the servers, the function starts a listener on port 8080:
lb := &NewLoadBalancer{
Servers: servers,
)
err = http.ListenAndServe(":8080", lb)
if err != nil {
panic(err)
}http.listenAndServe is a function from the built-in http package and it does exactly what you think. It listens on a port and serves incoming requests. The second argument is the handler (the function that runs when a new request comes in). Which is the LoadBalancer struct. But how does that work? How will our own struct handle incoming requests?
The second argument has to “implement” the Handler interface that looks like this:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}So LoadBalancer has to have a function called ServeHTTP:
func (lb *LoadBalancer) ServeHTTP(writer http.ResponseWriter, request *http.Request) {
nextServer := lb.NextServer()
res, err := lb.ForwardRequest(nextServer, request.RequestURI)
if err != nil {
panic(err)
}
defer res.Body.Close()
body, err := io.ReadAll(res.Body)
_, err = writer.Write(body)
if err != nil {
panic(err)
}
}In this function, we can finally call the other ones. First, it grabs the next server and then forwards the request to it. For now, if there’s an error the load balancer will panic (stop).
After that, the function reads the backend response and writes it to the client response (which the original caller will get):
body, err := io.ReadAll(res.Body)
_, err = writer.Write(body)Response in Go is a stream, just like in Node. It implements the Reader interfaces so we can read from it. res.Body needs to be closed after we’re done reading it:
defer res.Body.Close()Any code after the defer keyword will run when the current function exits.
The following function:
func ServeHTTP() {
server := NextServer()
res := ForwardRequest()
body, err := io.ReadAll(res.Body)
_, err = writer.Write(body)
if err != nil {
panic(err)
}
res.Body.Close()
}Is equivalent to this function:
func ServeHTTP() {
server := NextServer()
res := ForwardRequest()
defer res.Body.Close()
body, err := io.ReadAll(res.Body)
_, err = writer.Write(body)
if err != nil {
panic(err)
}
}Using defer can reduce human mistakes since it’s harder to forget.
To be continued
This is going to be a 3-part series. In the next part, we’ll implement health checks. It’s a critical feature of any load balancer. If a server is down, the load balancer should not forward requests to it.