
Redis can do more than you think
It's an in-memory key-value database with awesome features.

Introduction
Lots of people think of Redis as a cache system. While it’s true that it can be used as a key-value cache storage it can be much more than that.
Sponsor
If you want to be better at solving hard problems, and building real stuff, you’re going to love CodeCrafters.
Build your own docker, Git, Redis, and more.
I’m also a member of CodeCrafters. If you want to join you can get a 40% discount.
What is Redis?
Redis is a distributed key-value in-memory data structure store. Let’s first understand the definition.
Distributed. It means you can spin up 10 Redis instances listening on 10 different ports forming a cluster. There’s little additional configuration needed to do that. Two, to be more precise:
The first is enabling cluster mode:
# redis.conf file
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yesEach instance has a similar config file.
After running the servers the second step is to create a cluster:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7001 ... --cluster-replicas 1That’s it. Now you have 3 Redis instances working together in a cluster.
If you want to connect to “all” the servers you need to run redis-cli in cluster mode:
redis-cli -p 7000 -cYou can now create and query keys as if you had only one Redis server running. Like how easy was that? Try to do the same with MySQL.
So that’s the distributed part. Now let’s continue with the definition.
Key-value. This means Redis is not a relational database. It’s a key-value store. You can define keys and associate values with them. It’s similar to a hash map or associative array in PHP:
$redis = [
'key1' => 'it is a string',
'key2' => ['it', 'is', 'a', 'list'],
];In-memory. Redis is super fast since it stores everything in memory. On the other hand, MySQL only stores indices in the memory. Depending on your queries and indices it might or might not run thousands of disk reads. Redis won’t do something like that even if I’m not sure what I’m doing and I mess up my database a little bit. It’s important to note that it doesn’t mean if you restart your Redis instance you’ll lose your database. No. Redis will persist your data. It uses AOL (Append Only Log) and an RDB (Redis DB, which is essentially a file on your hard drive, just like MySQL or SQLite stores your tables in files). By default, it uses AOL works perfectly and it guarantees you won’t lose your data. The story of why Redis is in memory is quite cool. Salvatore Sanfilippo was building an analytics platform because he hated Google Analytics. He added some real-time statistics to the system. However, MySQL was quite slow for this specific use case. I imagine he was thinking something like “Well, memory should be way faster than the disk. Let me try something real quick.“ And Redis was born.
Data structure store or simply database. If I remember correctly Salvatore Sanfilippo called it a data structure store so I stick with this name. The point is, that Redis is a feature-rich database with lots of data structures that can handle lots of use cases. Some of them blew my head off.
Announcement

If you want to get better at Redis, check out ReelCode where you can solve real-world inspired Redis-related problems.
Anatomy of Redis commands
Before we dive in, let’s talk about commands. Each data type (such as lists or sets) has its own commands. Most of the time they start with a prefix that reflects the data type.
For example, all hash map commands start with the letter “H”:
HSET
HGET
Commands often use abbreviation:
HINCRBY where INC stands for “increment”
ZREVRANGE where REV stands for “reverse”
At first, it looks like ass. Well… After a long time too. It’s still better than Javascript frontend frameworks 😈
Lists
Lists are the same as arrays in most programming languages. They contain a list of values.
Most important commands
List is one of the few exceptions where command names start with different letters, and “L” not necessarily means “List”.
LPUSH - Adds an element to the left side of the list. It pushes to the beginning.
LPOP - Returns and removes an element from the left side (beginning).
RPUSH - Adds an element to the right side
RPOP - Returns and removes an element from the right side (beginning).
These four commands are the fundamentals of any queue or stack.
Most important use cases
Queues
Any time you use a Redis-backed job queue system (such as Laravel’s built-in) it uses a list under the hood.
FIFO can be implemented by:
RPUSH
LPOP
Using RPUSH is the same as using $items[] = $item in PHP.
Let’s add three numbers to a list:



Using LPOP it’s the same as $item = array_shift($items) in PHP:



What we just built with these two commands is a FIFO queue. This is how every job queue works.
Stacks
A stack is the opposite of a queue. It’s a LIFO data structure.
Once again, we can add three numbers to a stack:


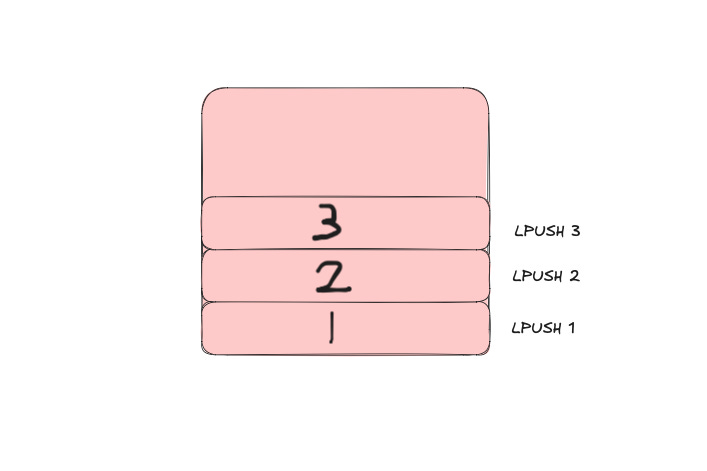
As an array, it looks like this [3, 2, 1] so when LPOP is executed it returns 3, 2, 1:
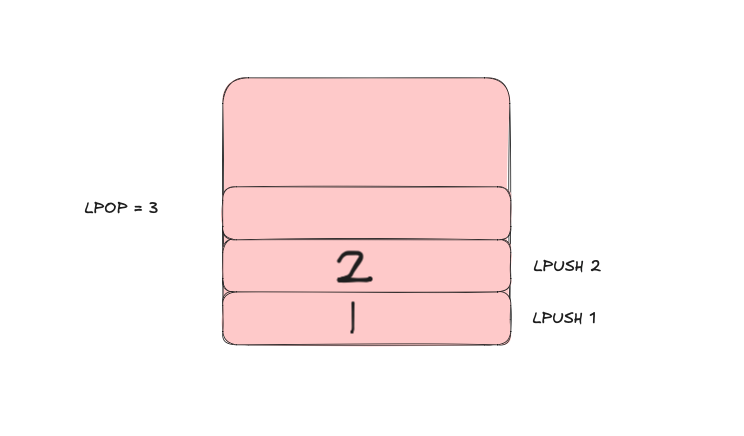


So what can be built by lists, queues, and stacks?
Job queues, message queues, or any other queue. Usually, we don’t build job queues from scratch, but you might need a retry queue, for example. You have a 3rd party API integration in your system but it’s down. In this case, you can queue the failed requests to retry them later. The same can be true for your own service.
Undo/redo stacks. Lots of applications implement undo/redo functionality. Stacks back them all. For more information, check out this post.
LRU caches. Very important data structure for “recently used” features. Examples include Spotify’s “Recently searched” items, Dropbox’s “Suggested from your activity” section, and Google Drive’s homepage. They are all variations of an LRU cache. Check out this post to learn more about it.
Similarly to LRU caches lots of applications implement some kind of recent activity or recently viewed items feature. For example, Amazon or any webshop will show you a recently viewed items list. Any todo app or project management software has some kind of recent activity feed. They can be Redis lists.
Temporary storage used by background jobs. Let’s say you run a scheduled command every night to process all the orders for that day. For each order, you dispatch a long-running job. After the whole process, you need a list of successfully processed order IDs. What’s the easiest way to do so? Just push the IDs into a Redis list. You don’t need a table in MySQL in most cases.
Temporary lists. Lots of application uses some kind of temporary list. For example, in both Spotify and Apple Podcasts there’s an “Add to queue” option when right-clicking on a song/episode. This queue can be a list in Redis with song/episode IDs.
Data buffering. Let’s say your application has some kind of social feature. For example, it’s an internal tool for companies where admins can publish news/events, etc for employees. Each time an interaction (comment, like, share, etc) happens you have to call another service (it can be your own service or a 3rd party). Think about the lifetime of a post. In the first “hour”, there can be 1,000s of interactions. 90% of the interaction happens in the first 10% of the post lifetime. Maybe you don’t want to call your other service 3,891 times in 9 minutes. In this case, you can use a Redis list as a buffer, where you are buffering interactions for a given post. After a certain size/time, you can do the real work. You can dispatch smaller jobs in batches (to smooth out the load), you can call a bulk API, etc.
There are dozens of other use cases for Redis lists. A good rule of thumb: if you have something “temporary” it’s a good indicator that a Redis list is a better option than a MySQL table.
Sets
Sets are pretty easy. They are lists with unique elements. A set is basically equivalent to this:
$set = collect($items)->unique();Most important commands
SADD - Adds an element to the set
SREM - Removes an element
SISMEMBER - Returns if a value is in the set or not. The command reads as “set, is member?“
SINTER - Returns the intersection of multiple sets
SUNION - Returns the union of multiple sets
Most important use cases
Tracking unique values. For example, storing IP addresses for analytics or security reasons. Storing the currently logged-in user IDs for status display, etc.
Removing duplicates. For example, you need to run a background job that removes some duplicate elements from a database. Just put everything into a set as you go and at the end, you’ll get a unique list of items.
Unique constraints. Sometimes it’s too slow to run a unique validation using the database. If you have a set with your items, you can just simply run a SISMEMBER command and find out if the given value is unique or not.
Sorted sets
Sorted sets are also pretty easy:
$sortedSet = collect($items)
->unique()
->sort();It’s a set that is sorted based on a score you can provide.
Most important commands
ZADD - Adds an element to the sorted set. “Z” stands for “sorted set”
ZREM - Removes an element
ZRANGEBYSCORE - Return multiple values in a given score range
Most important use cases
Leaderboards. Any type of leaderboard can be implemented with a sorted set. Each value is a user ID and each score is their points. On ReelCode you can put together a leaderboard with a detailed guide.
Statistics. For example, best-selling products. Values are product IDs and scores represent the number of sales. Any statistic that is based on a number, such as best-spending customers.
Analytics. For example, page views by a given IP address or user ID.
Voting system. Values would be user IDs and scores would be votes.
Priority management. For example, if your app has some project management-related features and you want to load the task board super fast you can store your data in a sorted set where values are task IDs and the scores are priorities so it is sorted by priority.
LRU cache. I already mentioned this earlier as an example in lists. However, a sorted set will give better performance. Read the details here.
Streams
A stream is an append-only data stream. It’s like an endless, append-only array. You have producers and consumers. A producer adds elements to the stream, and the consumer reads them.
Most important commands
XADD - adds a new item to the stream. X represents “stream” (s is already taken by sets)
XREAD - reads the last N item from the stream
XRANGE - reads data from the stream in a given time ID range
Each item has an ID and key-value pairs as value. IDs are usually timestamps. This is how you can add an item to a stream called messages:
XADD messages 1526919030474 type "order_created" order_id 75891This adds a new item with the ID of “1526919030474” which is a timestamp. The item itself is an object with the following attributes:
type: “order_created”
order_id: 75891
Most important use cases
Communication between microservices (message queue). A Redis stream can be the fundamental building block of an event-driven microservice architecture. If you don’t want to communicate via HTTP (where each service sends HTTP requests to each other) you’ll have to produce events from your services. For example, the Order service can publish an “order_created” event whenever a customer creates a new order. Every service that is interested in this event can consume the event stream and process the new entry. For example, a Statistics service can consume all “order_created” events to calculate reports. In this case, the Oerder service uses XADD to publish the event, and the Statistics service uses XRANGE to consume them. If you want to learn more about this topic check out my book Microservices with Laravel.
Event sourcing. The main point of event sourcing is that you don’t just store your state as a current snapshot in a database but you also maintain an event stream with everything that has happened in your application. Instead of just having an orders table with 100,000 rows you also have 300,000 events in a stream that describe the complete history of every order. This stream would contain everything. Events such as “order_created”, “order_updated”, “order_completed”, “order_canceled”, etc. This stream is the source of truth for the entire application. The basic idea is very similar to the previous point, but of course event sourcing has its own techniques and you can also use it in a monolith.
Message queues. This is also similar to the first point, but of course, you can use a Redis stream to implement any kind of message. You don’t necessarily have to have microservices.
Data processing. IoT devices are probably the most popular example. Imagine a data aggregator service where you accept millions of data entries from multiple devices each day. Having a super fast, append-only data stream is pretty important in this situation.
Real-time monitoring. In this situation, you need to collect and analyze different system health metrics from other services.
Any time you build a distributed system with multiple services you can probably utilize Redis streams in some way.
Pub/Sub
Pub/Sub stands for publish/subscribe. With this, you can implement messaging such as a notification service. Publishers produce messages into channels and subscribers consume them.
It’s similar to streams but has a major difference:
In a pub/sub system messages are not persisted and they are delivered to all active consumers in real-time. With a stream, you can set up a new consumer at any time and read any events you want. Pub/sub is about real-time communication.
In a stream, you can query specific events by their ID, and the consumer processes only the ones it’s interested in. With a pub/sub, a consumer gets every message from the channels it is subscribed to.
Most important commands
PUBLISH -Adds a new message to a channel. It is used by the publisher.SUBSCRIBE -Subscribes to one or more channels. It is used by the consumer.UNSUBSCRIBE -Unsubscribes from one or more channels. It is used by the consumer.
Most important use cases
Real-time notifications and alerts
Chat applications
Live updates such as dashboards
HyperLogLogs
Imagine you’re building an analytics platform, something like Google Analytics or SplitBee. You have 1 billion records in the page_views table. Each time a user opens your application you need to display the number of visitors.
Yes, you can create an index. But querying this table so often will be resourceful. Caching the results can work, yes. But it won’t really solve the core problem. It just helps to make it a bit faster.
When I first saw the word "HyperLogLog" written down I was panicking. I was thinking:
"Okay, so it's a log. But it's not an ordinary log, it's hyper. And it's not just a hyper log. It's a hyper double log. A hyper log log. What?!"
Then I read the first sentence of the documentation:
HyperLogLog is a probabilistic data structure that estimates the cardinality of a set.
Yeah, thanks, it didn’t help. Unfortunately, I don’t have a PhD.
So here’s my explanation:
It's a set that always takes 12kB of memory no matter how many elements it has.
Since it always takes the same amount of memory it means it doesn't actually store the items. Which means you cannot access the individual elements. You can only count them. There are no commands such as
zrange, etc.Counting the elements has a time complexity of O(1) which is super fast.
It has a 0.81% error rate. Meaning, it's not perfect. However, the error rate is so low it's neglectable in most cases.
So Redis can “store” your 1,000,000,000 page view record using 12kB of RAM and it returns the length in a few milliseconds. Or even faster. Redis sometimes responds under 1ms!
Most important commands
PFADD - adds an item to the HLL
PFCOUNT - returns the count
Most important use cases
Analytics. By far the most important use case for HLLs. If you want to count unique visitors, page views, IP addresses, etc you can just throw everything into an HLL and it’ll be super fast.
App usage analytics. If you want to understand how users use your app, for example, which feature is the most popular, etc you can count events in an HLL. Of course, to get more insight, you might use a stream with more detailed events as well.
Counting large data sets. Anything that is large and/or needed often and a SQL query would be too expensive.
Other data structures
Redis has even more data structures. Here are a few honorable mentions:
String. The simplest data structure of all. It’s often used to cache data. When you use
Cache::set(‘foo’, ‘foo’)in Laravel, under the hood it creates a string.Hash. Redis offers a good old hash map. If you want to store key-value pairs this is what you want.
Bloom filter. It’s another probabilistic data structure. It is used to test whether an element is a member of a set or not. Similarly to HLLs, it doesn’t actually store the whole item. It just stores the hash representation of a value. It uses very little memory so it’s super fast. You can use it in similar use cases as a set.
Geospatial data. You can use Redis for geolocation-based applications as well. To find out more check out Ride-sharing with Redis.
Autocomplete. Yes, Redis offers autocomplete, or auto-suggest as they call it. Find out more in the docs.
Conclusion
Redis is awesome. It’s a beast that can be used for so many things. And it’s super fast so lots of applications can benefit from using it in the right way.
One of the best things about Redis, in my experience, is that it’s quite old, it’s stable, fast, and it can solve modern problems really well.
It solves more problems than it creates.
Got any questions?
Thanks for the in-depth look at redis. I appreciate the two-part series you made that used redis to implement Uber - I was wondering if you'd do something similar that could demonstrate the pub/sub feature of redis? I attempted to implement a pub/sub between a python web-scraper that used beautiful soup and a laravel backend. But I found it difficult to make it work properly.
Redis is a beast!
Thanks for the breakdown, Martin.