
LRU caches part II
Replicating some of Spotify's features with in-memory LRU caches

This post is a continuation of a previous post. We implemented two LRU caches:
One with arrays
And another one with linked list
Now let’s compare the two from a performance point of view.
Performance
So far I haven’t talked about this but maybe you already guessed it. Compare these two operations.
Moving a node to the end of a linked list:
private function detach(Node $node): void
{
// O(1)
$node->prev->next = $node->next;
// O(1)
$node->next->prev = $node->prev;
}
private function append(Node $node): void
{
// O(1)
$node->next = $this->tail;
// O(1)
$node->prev = $this->tail->prev;
// O(1)
$node->prev->next = $node;
// O(1)
$this->tail->prev = $node;
// O(1)
$this->map[$node->key] = $node;
}Moving an item to the end of an array:
private function update(string $key): void
{
// O(N)
$idx = array_search($key, $this->items);
// O(1)
if ($idx === false) {
return;
}
// O(1)
unset($this->items[$idx]);
// O(N)
$this->items = array_values($this->items);
// O(N)
array_unshift($this->items, $key);
}When working with linked lists there are no loops, no O(N) operations at all. Everything is O(1) since all we need to do is manipulate pointers.
When working with arrays everything is O(N) except two lines.
Here’s the Big O notation table of an array:

And here’s the same table of a linked list:

Of course, the big win for arrays is the random access which is not possible with linked lists.
In the case of an LRU cache, however, the overall time complexity is close to O(1) with linked lists.
So let’s benchmark it:
\Illuminate\Support\Benchmark::dd([
'array:1_000' => fn () => $benchmark(
new LRUCacheArray(1_000), 1_000,
),
'array:10_000' => fn () => $benchmark(
new LRUCacheArray(10_000), 10_000,
),
'array:20_000' => fn () => $benchmark(
new LRUCacheArray(20_000), 20_000,
),
'array:100_000' => fn () => $benchmark(
new LRUCacheArray(100_000), 100_000,
),
'linked_list:1_000' => fn () => $benchmark(
new LRUCacheLinkedList(1_000), 1_000,
),
'linked_list:10_000' => fn () => $benchmark(
new LRUCacheLinkedList(10_000), 10_000,
),
'linked_list:20_000' => fn () => $benchmark(
new LRUCacheLinkedList(20_000), 20_000,
),
'linked_list:100_000' => fn () => $benchmark(
new LRUCacheLinkedList(100_000), 100_000,
),
]);The results are mind-blowing:
1,000 items
array: 49ms
linked list: 1.7ms
10,000 items
array: 2,400ms → 2.4s
linked list: 4.9ms
20,000 items
array: 9,884.078ms → 9.8s
linked list: 19ms
100,000 items:
array: 275,203.395ms → 275s → 4.5 minutes
linked list: 64ms
An array-backed cache with 1,000 items takes the same time as a list-based cache with 100,000 items.
The difference with 100,000 items is 4,300x.
This is the power of an O(1) algorithm/data structure.
LRU cache with Redis lists
When it comes to caching Redis is the first choice of lots of developers. For a good reason, it’s fast and pretty flexible.
Also, when you want to have an LRU cache in a project that runs in a cluster you cannot just throw an LRUCacheLinkedList class to the problem. Your app runs on multiple servers so an in-memory cache on server A cannot be used by the same user when his request gets served by server B. You have two options: create your own cache server based on the LRUCacheLinkedList class or use Redis. Let’s go with the second one.
Lots of people know Redis lists so let’s see how they perform.
The LRUCacheRedisList class needs two additional properties:
class LRUCacheRedisList extends LRUCache
{
private string $listKey;
private string $mapKey;
public function __construct(
int $capacity,
string $listKey,
string $mapKey,
) {
parent::__construct($capacity);
$this->listKey = $listKey;
$this->mapKey = $mapKey;
}
}It accepts two Redis keys: one for the list and one for the hashmap.
Putting an item into the cache is quite simple:
public function put(string $key, mixed $value): void
{
if (Redis::llen($this->listKey) >= $this->capacity) {
$removedKey = Redis::lpop($this->listKey);
Redis::hdel($this->mapKey, $removedKey);
}
Redis::rpush($this->listKey, $key);
Redis::hset($this->mapKey, $key, $value);
}Let’s see:
llenreturns the length of the list.lpopreturns and removes the first element.hdeldeletes a key from a hashrpushpushes an item at the end of the listhsetsets a key in a hash
It’s exactly the same as with arrays, but instead of array functions, we use Redis commands. The logic is also the same:
If the length of the list exceeds the capacity it removes the least used item which is located at the beginning of the list. It also removes the key from the hash.
Otherwise, it pushed the new item to the end of the list. It also sets the new key in the hash.
Retrieving an item is also very simple:
public function get(string $key): mixed
{
$value = Redis::hget($this->mapKey, $key);
if (!$value) {
return null;
}
Redis::lrem($this->listKey, 0, $key);
Redis::rpush($this->listKey, $key);
return $value;
}It checks if the key is present in the hash. After that, it removes the item from the list and pushes it at the end. This is also the same logic as it was with arrays.
Performance
Fortunately, the Big O notations are shown in Redis docs:
public function put(string $key, mixed $value): void
{
// O(1)
if (Redis::llen($this->listKey) >= $this->capacity) {
// O(1)
$removedKey = Redis::lpop($this->listKey);
// O(1)
Redis::hdel($this->mapKey, $removedKey);
}
// O(1)
Redis::rpush($this->listKey, $key);
// O(1)
Redis::hset($this->mapKey, $key, $value);
}So put is a simple O(1) operation. Nice.
Let’s see get:
public function get(string $key): mixed
{
// O(1)
$value = Redis::hget($this->mapKey, $key);
if (!$value) {
return null;
}
// O(N)
Redis::lrem($this->listKey, 0, $key);
// O(1)
Redis::rpush($this->listKey, $key);
return $value;
}Unfortunately, it’s O(N) because of lrem.
Let’s see how it does in the benchmark:
\Illuminate\Support\Benchmark::dd([
'array:1_000' => fn () => $benchmark(
new LRUCacheArray(1_000), 1_000,
),
'array:10_000' => fn () => $benchmark(
new LRUCacheArray(10_000), 10_000,
),
'linked_list:1_000' => fn () => $benchmark(
new LRUCacheLinkedList(1_000), 1_000,
),
'linked_list:10_000' => fn () => $benchmark(
new LRUCacheLinkedList(10_000), 10_000,
),
'redis_list:1_000' => fn () => $benchmark(
new LRUCacheRedisList(
1_000, 'items_list', 'cache_list'), 1_000
),
'redis_list:10_000' => fn () => $benchmark(
new LRUCacheRedisList(
10_000, 'items_list', 'cache_list'), 10_000
),
]);The results are:
1,000 items
array: 49ms
linked list: 1.7ms
Redis list: 644ms
10,000 items
array: 2,400ms → 2.4s
linked list: 4.9ms
Redis list: 8,641ms → 8.6s
Well, Redis isn’t that fast after all? These results look horrible, but it’s not that simple. The truth is that it’s not an apple-to-apple comparison. Redis is a separate process. It’s a server communicating with the application over TCP. During these tests, the PHP process probably opened and closed thousands of TCP connections which is an enormous overhead. Compared to using the LRUCacheLinkedList from the same project. A better comparison would be to put these classes into different projects, spin up dedicated TCP servers, and serve them via an API. I won’t do that now because it doesn’t sound realistic.
The other problem is that get() has a time complexity of O(N). It should be better so let’s improve it!
Do you like this post so far? If yes, please share it with your friends. It would be a huge help for the newsletter! Thanks.
LRU cache with Redis sorted sets
The problem with get() is that Redis needs to remove the currently accessed item from the list and it’s an O(N) operation. Unfortunately, I don’t know any way to fix this issue using a list.
What if use sorted sets? In a previous post I talked about them in great detail, but here’s the executive summary: it’s a unique list where each member has a score. The set is sorted based on the scores.
The score can be anything until it’s an integer. For example, a timestamp that represents the date when the member was last accessed. The fact that a sorted set is sorted can also be advantageous. Searching and removing an element from an unsorted list is O(N) just as we’ve seen before. But if the list is sorted it becomes O(log(N)) since binary search can be used.
O(log(N)) doesn’t sound too good but it’s way better than O(N). Just look at this graph:
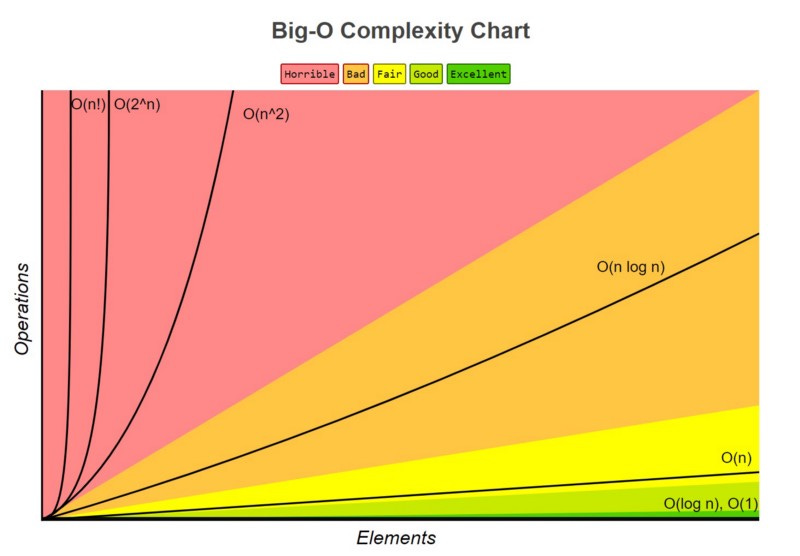
Don’t confuse O(log n) with O(n log n) in the orange area. O(log n) is the flat line at the bottom you just missed.
A quick question for you:
Since a sorted set is unique all the time, we don’t actually need to find and remove the element that was just accessed. We can just simply add it again to the set.
If you check the documentation of ZADD you can see it has a time complexity of O(log(n)). When you add a new member to a sorted set it needs to do some other work such as removing other occurances of the same value. It has additional cost, but it’s still cheaper than working with lists.
This is what the put() method looks like:
public function put(string $key, mixed $value): void
{
if (Redis::zcard($this->setKey) >= $this->capacity) {
$result = Redis::zpopmin($this->setKey);
$keys = array_keys($result);
Redis::hdel($this->mapKey, $keys[0]);
}
Redis::zadd($this->setKey, now()->getPreciseTimestamp(), $key);
Redis::hset($this->mapKey, $key, $value);
}The logic is the same, but with different functions:
zcardreturns the length of the set. card stands for cardinality.zpopminreturns and removes the member with the lowest score. In this case, the lowest score is the smallest timestamp. In other words, it removes the least recently used item.zaddadds a new member to the set. The set remains sorted and unique. For the score I use the precise timestamp that includes microseconds as well.
Retrieving an item is also quite simple:
public function get(string $key): mixed
{
$value = Redis::hget($this->mapKey, $key);
if (!$value) {
return null;
}
Redis::zadd($this->setKey, now()->getPreciseTimestamp(), $key);
return $value;
}It just adds the same element again with a new timestamp and the whole set gets sorted.
That’s it. It was even simpler than using a list.
Performance
Let’s estimate the time complexity of put:
public function put(string $key, mixed $value): void
{
// O(1)
if (Redis::zcard($this->setKey) >= $this->capacity) {
// O(log(N))
$result = Redis::zpopmin($this->setKey);
$keys = array_keys($result);
// O(1)
Redis::hdel($this->mapKey, $keys[0]);
}
// O(log(N))
Redis::zadd($this->setKey, now()->getPreciseTimestamp(), $key);
// O(1)
Redis::hset($this->mapKey, $key, $value);
}Put became O(log(N)) which is not that bad compared to O(N). If get is also O(log(N)) then we should see a difference in the benchmark results.
Here’s the complexity of get:
public function get(string $key): mixed
{
// O(1)
$value = Redis::hget($this->mapKey, $key);
if (!$value) {
return null;
}
// O(log(N))
Redis::zadd($this->setKey, now()->getPreciseTimestamp(), $key);
return $value;
}It’s also O(log(N)). Now let’s compare the two solutions:
\Illuminate\Support\Benchmark::dd([
'redis_set:1_000' => fn () => $benchmark(
new LRUCacheRedisSet(
1_000, 'items_set', 'cache_set'
), 1_000),
'redis_set:10_000' => fn () => $benchmark(
new LRUCacheRedisSet(
10_000, 'items_set', 'cache_set'
), 10_000),
'redis_list:1_000' => fn () => $benchmark(
new LRUCacheRedisList(
1_000, 'items_list', 'cache_list'
), 1_000),
'redis_list:10_000' => fn () => $benchmark(
new LRUCacheRedisList(
10_000, 'items_list', 'cache_list'
), 10_000),
]);1,000 items
array: 49ms
linked list: 1.7ms
Redis list: 644ms
Redis set: 573ms
10,000 items
array: 2,400ms → 2.4s
linked list: 4.9ms
Redis list: 8,641ms → 8.6s
Redis set: 4,792ms → 4.7s
When working with a larger dataset using a sorted set is almost 2x better than using a list. With 20,000 items the difference is almost 2.5x.
I know these Redis results seem very bad compared to arrays and linked lists. But as I mentioned it’s not an apple-to-apple comparison.
What we should compare is this:
arrays vs linked lists where the latter performs better by a huge factor
Redis lists vs Redis sets where sets perform better by a factor of 2x
The main lesson is that choosing the right data structure can achieve great results.
This post is starting to get a bit long so take a quick break and vote:
Loading...
LRU cache in action
Finally, let’s put together a simple API that simulates the “Recent Searches” feature on Spotify.
I used large numbers in benchmarks to see the difference between the different implementations. However, in the real world, an LRU cache is often used with a smaller capacity. For example, on Spotify, I only see my most recent 16 searches. On Google Drive’s home page, there are only 20 recently used files. On Dropbox, I can see only 3 items in the “Suggested from your activity” panel.
But efficiency still matters. A lot. You need to multiply these small numbers with millions of users. So in a lot of cases, the capacity is smaller but there are millions of these hash maps and lists.
In order to demonstrate an LRU cache in action, we need one more function. The cache needs to be able to return all stored items:
/**
* @return array<int, mixed>
*/
public function getAll(?callable $callback = null): array
{
$items = Redis::hgetall($this->mapKey);
if ($callback) {
return collect($items)
->map(fn ($item) => $callback($item))
->all();
}
return $items;
}Since each implementation has a hash map, this function is very simple. It just returns all items from the map. I added an optional callback that can be used to transform to stored elements. It’ll come in handy in a minute.
I want to demonstrate two use cases of an LRU cache:
Use it as a simple cache. For example, a user wants to view artist #15. Instead of querying it from the database, we can use
$cache→get(15)Show the whole list just as in the examples I listed above (Spotify, Drive, Dropbox, etc).
As a simple cache
Since each user has their own cache the app needs to create keys such as:
artist:recent:cache:1for the hash mapartist:recent:items:1for the sorted set
Each key is prefixed with a user ID. In Laravel we can bind an instance of LRUCacheRedisSet at the beginning of every request with a user ID:
namespace App\Providers;
class AppServiceProvider extends ServiceProvider
{
public function boot(): void
{
$this->app->bind(
LRUCache::class,
function () {
return new LRUCacheRedisSet(
10,
'artist:recent:keys:' . request()->user()->id,
'artist:recent:cache:' . request()->user()->id,
);
},
);
}
}It can be injected into the Controller and can be used to retrieve an artist:
namespace App\Http\Controllers;
class ArtistController extends Controller
{
public function __construct(private readonly LRUCache $cache)
{
}
public function show(int $id)
{
$artist = unserialize($this->cache->get($id));
if (!$artist) {
$artist = Artist::findOrFail($id);
$this->cache->put($artist->id, serialize($artist));
}
return ArtistResource::make($artist);
}
}It’s important to note that the cache stores serialized objects. They are deserialized after calling the get method.
Of course, a cache with a capacity of 10 won’t do magic in a global artist search feature. For that, you probably need another user-independent cache. A global cache with the most popular artists.
However, if you think about the left side of Spotify:

These 5 artists (and playlists) cover at least 70% of my Spotify usage. They contain more than 1,000 songs. So if a personalized LRU cache stores the contents of these 5 “things” I probably hit Spotify’s DB like 3 out of 10 requests. The remaining 7 times their Redis cluster serves me.
As a “most recent” cache
Another API endpoint returns the list of the most recently searched artists:

This is the whole hashmap so the logic is very simple:
namespace App\Http\Controllers;
class RecentSearchController extends Controller
{
public function __construct(private readonly LRUCache $cache)
{
}
public function index()
{
$artists = $this->cache->getAll(
fn ($item) => unserialize($item)
);
return ArtistResource::collection($artists);
}
}The callback deserializes the contents of the cache.
As you can see, understanding and building different kinds of cache implementations was quite a long process. However, using it is as easy as it gets. This is true for lots of data structures.
What else an LRU cache can be used for? The official Redis website sums it up so great that I paste a section here:
Web browsers
Web browsers, such as Chrome and Firefox, employ LRU Cache to store frequently accessed web pages. This allows users to quickly revisit pages without the need to fetch the entire content from the server, enhancing the browsing experience and reducing latency.
Operating systems
Operating systems use LRU Cache for memory management, specifically in the page replacement algorithms. When a program requires more memory pages than are available in physical memory, the operating system decides which pages to evict based on the LRU principle, ensuring that the most recently accessed pages remain in memory.
Content delivery networks (CDNs)
CDNs, which distribute web content to servers located closer to the end-users, utilize LRU Cache to store popular content. By caching frequently accessed data, CDNs can deliver content faster to users, reducing the load on the origin server and improving website performance.
Databases
Databases, especially those handling large volumes of data, use LRU Cache to store frequent query results. This reduces the need to access the underlying storage system for repeated queries, leading to faster query response times and optimized database performance.
Mobile applications
Mobile applications, particularly those requiring offline access or rapid data retrieval, implement LRU Cache to store frequently accessed data. This ensures that users can access key features of the app without delays, even in low connectivity scenarios.
Source: Redis website
Don’t forget to clone the repository.
If you have a question or feedback don’t forget to leave a comment!
A bit out of scope of article ctx, but worth mentioning for users adopting this, is setting up a persistent connection (pconnect) and using a socket rather than tcp/ip.
In addition, the article covers the scope of a cluster, in which a redis service is a great choice.
However for a single server or vps, a better option may be Swoole table thru laravel octane.
A Swoole table can also function as a shared intermediate layer to a redis cluster.
Whether it's worth it in terms of complexity, is to be evaluated thru a cost / benefit analysis.
Hi Martin, interesting topic there. I loved this, give me insights. never do optimation like using LRU Caches