
Launching your own SaaS - Part 6: Multi-tenancy
I'm documenting the entire process of building my 6th SaaS product

Introduction
This is a new series where I’m documenting the entire process of building my 6th SaaS product.
It’s an app that connects all the knowledge in your team and makes it super accessible:
It’s called Horizontal.
It is a multi-tenant application.
What is multi-tenancy?
Multi-tenancy in most situations refers to an application that is used by companies, and each company has its own users.
Each company has its own “workspace” in your product, and users only see their company’s data.
Think about Slack, for example. You log into a workspace that is used by your company. Obviously, each company sees its own data.
The question is: why is this challenging at all?
Databases
Since a company can only see its own data, you need to implement some kind of data isolation. You have two main options:
Single database
Multiple databases
Single database
A single database means you have one database server running with only one database, and you segment the data by using a foreign key. Each table that is segmented based on the tenant has a key like:
tenant_id
company_id
team_id
customer_id
etc
A table looks like this:

This has one big advantage that usually tricks people:
It’s really fast to implement
You “just” add a foreign key to segmented tables, modify the queries with an additional `where` statement, and you’re done.
The problem is that people often confuse speed with simplicity.
They often say “this is the simplest solution so you should start with this.”
But is this really that simple?
Let’s see:
If you forget the tenant_id in a delete query, you can ruin the data for hundreds of companies.
The database will grow huge pretty soon since you store everything in one place.
A random bug in a random query could expose highly sensitive data to another company (tenant 2 sees the data of tenant 1)
In other words, by doing the “simple” solution, you introduce:
Additional risk
Potential performance problems
Serious security issues
and you make debugging just a bit more complex. Instead of opening a table, you always need to use filters and where expressions to see the data of one company.
This is not simple.
This is complex.
The simple solution, in my opinion, is:
Multiple databases
It means that you have one database server, but each tenant has a dedicated database.
This is data isolation at a way higher level:
Less risk. Whatever you do in one database remains in that database. Data leakage is not possible anymore. If you forget a where statement, you “only” ruin one company.
Smaller databases. What was an index before now becomes a dedicated database. Fewer performance problems.
More secure since data is completely isolated.
And you still have only one MySQL or Postgres instance:
Deployment remains simple
Upgrading versions remains simple
The main disadvantages are:
Slower implementation
Debugging is also a bit more complicated since you have to go to the appropriate database first. But it’s not a big disadvantage in my opinion.
It has another indirect advantage: you have two kinds of databases if you use some kind of package (usually):
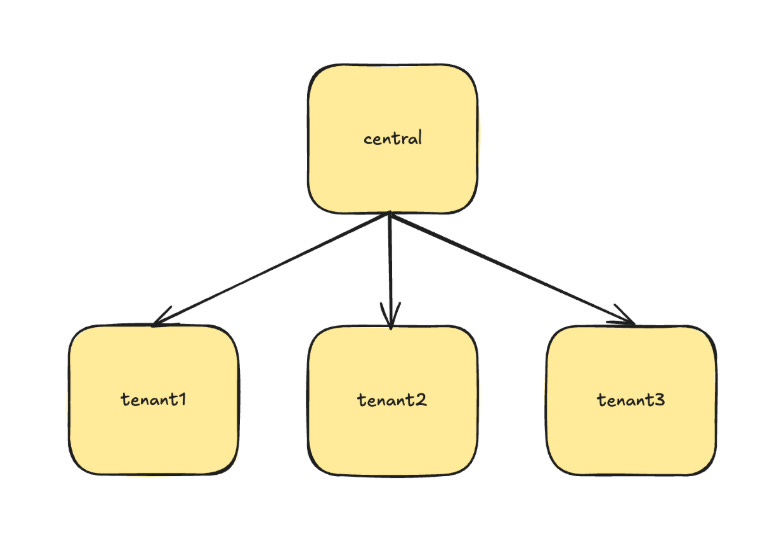
Central
Tenant
The tenant database contains tenant-related data. This contains the usual stuff like products, categories, etc.
The central database contains data that is not tenant-related. This data belongs to the application. For example, a list of tenants with database connection information (such as the databases for “Company XYZ” is called “tenant-1234” etc).
Most packages require you to do that since they need a central database to store tenants, domains, etc.
The central database also contains “admin-related” information, such as admin users who can see internal dashboards (like application-related dashboards, list of tenants, usage information, etc).
So out of the box, you’ll get an “admin” database where you can see and manage tenants.
In Horizontal I use the stancl/tenancy package. You only need to change two things in the code.
You need to separate your migrations. Tenant-related migrations go into a dedicated “tenant” folder:
Everything else is for the central database:
tenants
domains (if you use a subdomain-based routing)
job (if you use a database for queues)
The last one is important.
Jobs usually should live in the central database because you have one queue and a cluster of workers that can pick any of the available jobs. Then, in the job, you can decide which tenant database to use (or the package takes care of it completely).
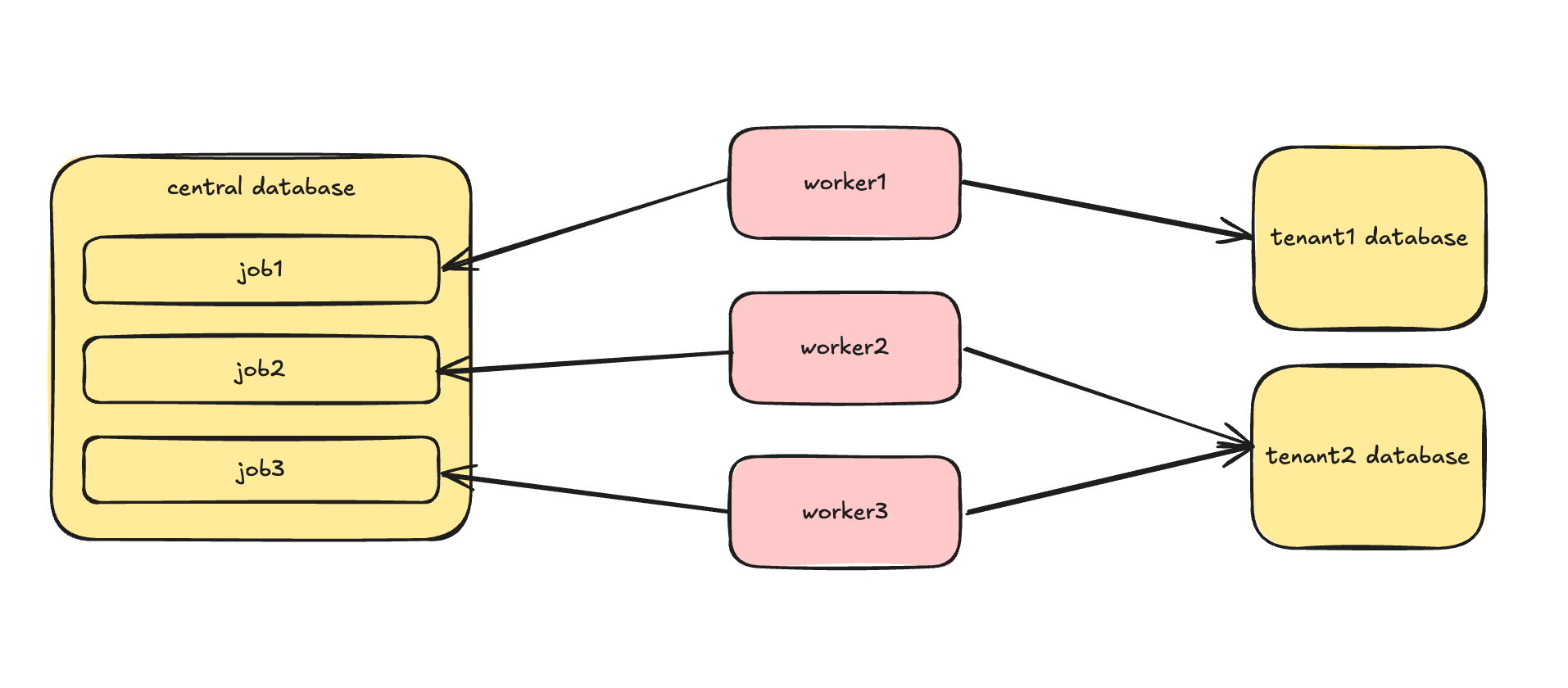
As you can see, workers pick jobs from the central database and do the work in the appropriate tenant database.
Yes, you can mess this up. For example, worker1 can overwrite tenant2’s database with tenant1 data, but you only need to handle this once. Once you create your own worker class that selects the appropriate database based on some criteria.
In the one database setup, you need to modify every query in the entire application:
ORM-style queries
Query builder-style queries
Raw queries in strings
etc
In my opinion:
Using a single database is complicated and risky
Using multiple databases is simple and secure
Support
If you want, you can support Horizontal in different ways:
Join the project as a marketer
Join the project as a developer
Bring your team as beta testers
If you’re interested, drop me an email at martin@martinjoo.dev or book an appointment in my calendar here.
Multi-tenancy is where scalability meets complexity, i really liked how you made it clear and practical.
I feel using same database or same logical queue for all tenets leads to Noisy neighbour issue.
One tenet can push more jobs into queue and an other tenant would be waiting.
I have faced this same issue where we 1000 clients. We go with same approach where single central database to hold tenet meta data.
High our product is analytics tool which helps you to configure your database and you can do reporting with different type of reports from table to charts and pivots.
Our setup single version of application server and singe global redis queue and work setup for 1000 clients.
Problem we have dashboard which is collection of reports. A dashboard can have 50 reports. Which means 50 sql queries. We thought to optimise this for better user experience.
Previous user need to wait for 50 queries to finish. So I implemented a queue job style to handle the query and websockets to send data to frontend.
Our stack Laravel 10 and vue 2. It look pretty decent on our staging environments . Once it on prod things are still slow. Tenant starts complaining us.
We figure out having single queue was problem. We raised works count but it started creating context switching issue. It doesn’t solved. Later we made a logical queue inside a redis.
Idea is having separate logical queue with tenant I’d. Now we avoided noisy neighbour issue. Still the context switching issue is there as we need 1000 process on worker servers.
Later we landed on ideal middle ground not all tenant are having high traffic. So now we have done sort of consistent handling logic to push job on queue with flags for those clients and we have spinned a separate workers for those client.