

Introduction
Around September 2024 I built a LeetCode alternative. My plan was to create better, more practical problems/challenges and launch it as a small product.
It had a promising start, but eventually I shut it down because it had 0 paying customers, and the system was a bit too complex to maintain it as a free app.
At least now, I can share how it works because it has some interesting stuff:
Remote code execution
Docker container pooling
Asserting user submissions
Get the book
I also put together a 72-page book, that contains more knowledge and the whole 13k line codebase to the project.
High-level design
Docker inside Docker
Container pools
Code execution
Asserting test cases
Init and tear down tasks for containers
Package oriented design
How to navigate the source code
Code execution
Now that we have a container pool it’s time for code execution.
There’s an executor struct:
type Executor struct {
containerPool *ContainerPool
config *config.Config
logger *zap.Logger
}As you can see, it contains a container pool instance. The only important function on this type is Execute:
func (e *Executor) Execute(
ctx context.Context,
sub *submission.Submission,
lang *language.Language
) (r *output.Result, retErr error) {
if sub.StatusId >= submission.TestsPassed {
return nil, fmt.Errorf(
"submission has already been executed: %v", sub
)
}
id, err := e.containerPool.Get(lang)
if err != nil {
return nil, fmt.Errorf(
"unable to get container (%s): %w", lang.ID, err
)
}
defer func() {
pushErr := e.containerPool.PushBack(lang, id)
if pushErr != nil {
retErr = pushErr
}
}()
}Code execution needs a running container so the first is grabbing one from the pool. When the Execute function returns (either with a result or an error) the ID is pushed back to the pool by the deferred function.
The Execute function accepts a Submission argument. This type represents the user’s submission and it has fields like these:
type Submission struct {
ID string
SourceCodeDecoded string
SourceCodeEncoded string
LanguageId string
ProblemId string
UserID string
StdoutRaw string
Stderr string
StdoutLines []string
StatusId int
SystemErr string
}The first set of fields (from ID to UserID) are available when the user hits the submit button. Such as which programming language the user used, what’s the problem ID the user is trying to solve, etc.
The second set of fields (from StdoutRaw to SystemErr) are the result of the execution. Such as what’s the output, any error that happened, and a status (passed, failed, etc).
The fact that we can differentiate between these two sets of fields is a good indicator that there probably should be two different types:
Submission
SubmissionResult
However, I store all of these in one table so it was just easier to keep them together. Also, it’s not a huge object (or a huge table) so it doesn’t cause any problems yet. I often do this, by the way. The first version should be as simple as possible. As time goes on and features grow in complexity, then it’s time to refactor things like this.
So we have a container ID and the submission. They often go together since every submission will have a running container so I created another type called Container:
type Container struct {
ID string
languageID string
problemID string
submissionID string
}It’s really just a container for a submission and a container ID and implements only a few basic functions that we’ll see soon.
In the Execute function, I create a container which we’ll use later:
c := container.NewContainer(id, sub.LanguageId, sub.ProblemId, sub.ID)So now we have the source as a string and a running container. Without the context of LeetCode, just think about how would you the code into the container?
For me, this seems the most simple way:
echo "source code here" >> solution.php
docker cp cc5564edfe81:/usr/solution.php solution.phpSo we simply create a file and copy it to the container.
And then the execution would be something like that:
docker exec cc5564edfe81 php /usr/solution.phpThe docker CLI offers a function:
CopyToContainer()It takes a few arguments, but the most important is content. However, we cannot copy a php file into a container. The file has to be a TAR archive. Even if it only contains a single file.
I/O in Go
More specifically, CopyToContainer takes an io.Reader for a TAR archive. As we discussed in the last part, when it comes I/O operations, everything is an io.Reader or io.Writer in Go.
So let’s understand them first.
They are interfaces with a single function:
writer.Write(p []byte) (n int, err error)
reader.Read(p []byte) (n int, err error)They both have the same signature which seems weird at first.
Write takes a byte array which contains the content we want to write. It returns an integer that contains how many bytes were successfuly writter. If everything went well then the length of the input should be equal to the return value:
len(p) == nIt also returns an error if something went wrong.
Read also takes a byte array and also returns an integer. Coming from PHP the logical signature would look like this:
reader.Read() (string, error)Which is based on fread:
fread(resource $stream, int $length): stringHowever, PHP is “cheating” here. The original fread function from C looks like this:
fread(buffer, 1, BUFFER_SIZE, file)The first argument, buffer, is a pointer where the read data will be stored. The same thing happens in Go:
buf := make([]byte, 1024)
reader.Read(buf)Read() will read 1024 bytes into the buf array.
Usually, Go or C-like reading is more memory-efficient, has better performance, and offers more control since we control the buffer.
On the other, fread doesn’t require a dedicated paragraph to explain and PHP is able to have different signatures for reading and writing data:
fread(resource $stream, int $length): string
fwrite(resource $stream, string $data, ?int $length = null): intSo I/O looks like this in Go:
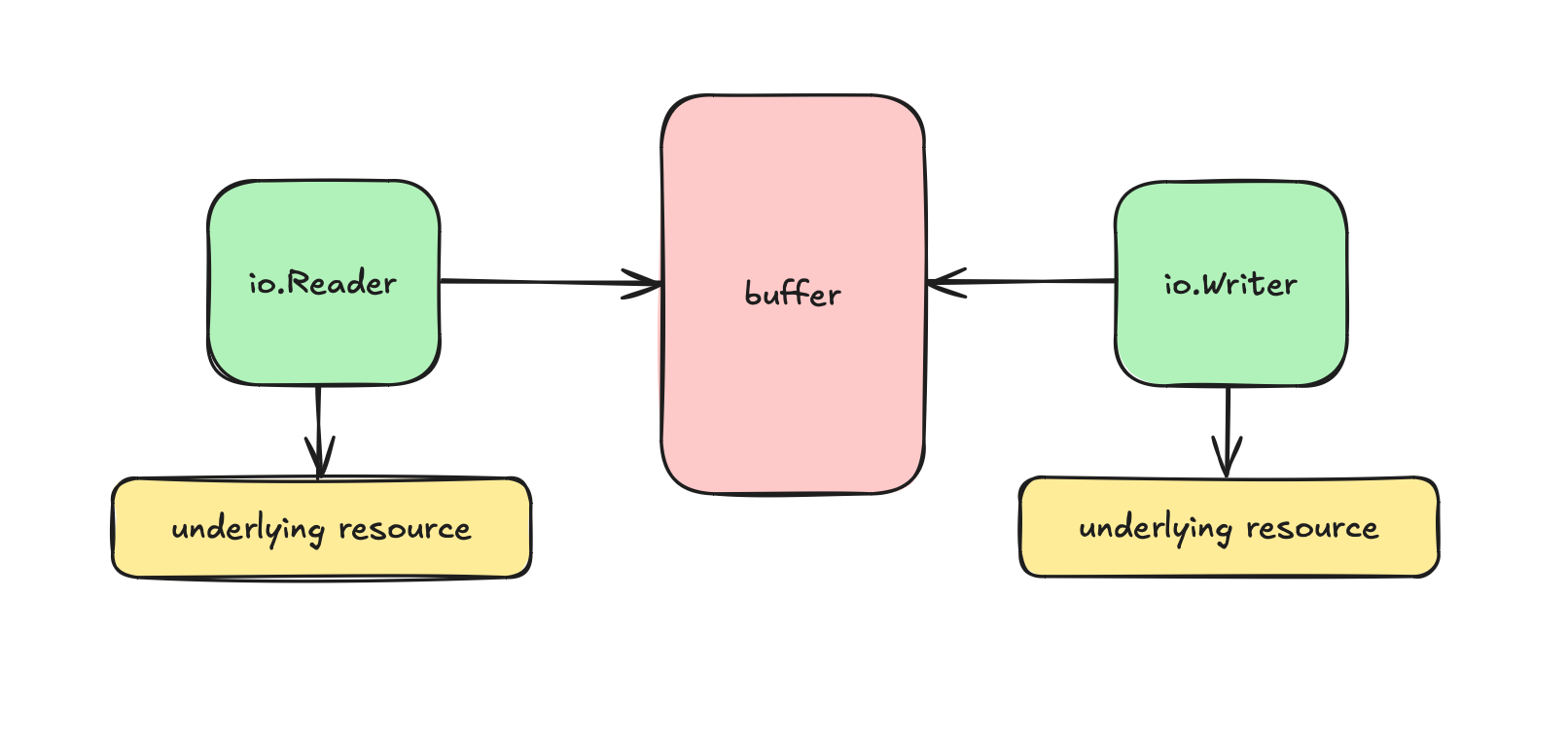
io.Reader and io.Writer are interfaces and they have hunderds of different implementations in the Go stdlib and the Go ecosystem in general.
Which gives developers an unmatched experience, becase everything (like literally, everything that has to do something with I/O) works the same:
Files
Buffered IO
TCP connection
HTTP requests
Databases
Arrays
Buffers
Your own array or buffer-like structures
Crypto (encription/decription)
Compression/decompression
Image processing
stdout, stdin
Streaming
Template rendering
IPC
Creating a TAR archive
Keep reading with a 7-day free trial
Subscribe to Computer Science Simplified to keep reading this post and get 7 days of free access to the full post archives.