


Building a key-value store part 5 (eviction policies)
Understanding and implementing Redis' LRU eviction policy

Introduction
This is part 5 of a 6-part series. In the last part, we ended up with an in-memory store that persists its data in two different ways:
AOL
RDB
But what happens when the data in memory is too large? For example, your server has 4GB of RAM but your database is so big it doesn’t fit in. Redis won’t crash in situations like this. It starts evicting keys.
If you want to try out the end product you can download the binaries here. Check out the project’s README. If there’s a problem you can build your own binaries with make build
Eviction policies
How to evict keys when the program needs to free up memory is a surprisingly complicated question.
Here’s a list of available eviction policies in Redis:
noeviction: No eviction, errors on write.
allkeys-lru: Evict least recently used keys.
allkeys-lfu: Evict least frequently used keys.
volatile-lru: Evict least recently used keys with expiration.
volatile-lfu: Evict least frequently used keys with expiration.
allkeys-random: Evict random keys.
volatile-random: Evict random keys with expiration.
volatile-ttl: Removes keys with
expirefield set totrueand the shortest remaining time-to-live (TTL) value.
You don’t need to understand all of them. Most Redis deploys use one of the following: noeviction, allkeys-lru, allkeys-lfu.
noeviction means there’s no eviction. If you send a write command and the memory limit is reached Redis returns an error.
allkeys-lru means Redis evicts the least recently used keys. If you have 5 keys and they were accessed in the following order:

key “a” was accessed right now, while key “e” was accessed 5 minutes ago. In this case, allkeys-lru removes “e” from memory. This is probably the most commonly used eviction policy because it works great for lots of use cases. We’re going to use this one in the application.
LRU is a well-known data structure/algorithm. I published a 2-part series that describes everything in great detail. You can read it here:

In this post, I’m not going to go into the small details but of course, I’ll give a good summary.
The interesting thing is that Redis does not actually use a real LRU. They use an approximation algorithm that produces very similar results to a classic LRU. They do this to save memory. You can read more about this in the docs. Tedis will use a standard LRU implementation.
allkeys-lfu is another interesting eviction policy. It keeps frequently used keys and removes the least frequently used (LFU) keys. Redis maintains a counter that tracks the “popularity” of the keys. When memory is low it prefers a key that was accessed 1,000 times in the last 10 minutes over another key that was only accessed 100 times.
In an LRU setting, the popular key might be evicted if it had lower traffic in the last X minutes. In an LFU setting, the chance of this happening is much lower. It is still the most frequently used key.
Another interesting thing is that they don’t use real counters. They use a probabilistic counter called a Morris counter. It’s also an approximation (similar to LRU) because it uses less memory/resources. You can read more here.
LRU
As I said, you can check out the 2-part series about LRU but here’s a summary.
Let’s say we have an LRU cache with a capacity of 3. If a user reads the following items in the following order:
#1
#2
#3
The LRU cache looks like this:

If the user accesses #4 then #1 gets evicted (since the capacity is only 3) and #4 gets pushed at the beginning (as the most recently used item):
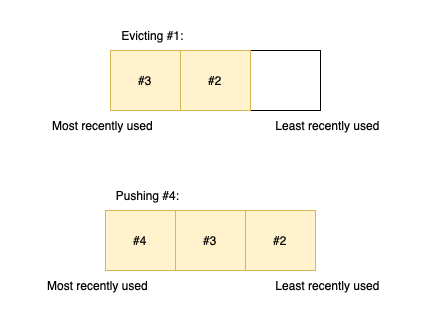
When an existing element is accessed it has to be pushed at the beginning of the cache:

This is how LRU works in a nutshell.
To implement it we need two things: a hashmap with the keys, and an array (or linked list) with keys:
type LRU struct {
Map map[string]string
Items []string
Capacity int
}The hashmap is used for quick access. Retrieving an item is an O(1) operation. It takes constant time no matter if you have 10 or 10,000 items. The array is needed to maintain the order of items.
The map looks like this:
{
"key1": "key1",
"key2": "key2",
}We want to use this LRU to get the least recently used keys. Because of that both keys and values contain the same data in the map.
This is how a new key can be added to the cache:
Keep reading with a 7-day free trial
Subscribe to Computer Science Simplified to keep reading this post and get 7 days of free access to the full post archives.