
Building a key-value store part 4
Designing and building a Redis-like in-memory key-value tree store

Introduction
This is part 3 of a 6-part series. In the three two parts, we’ve created a simple in-memory, key-value store that starts a TCP server and accepts requests from clients. It can store binary search trees in the memory. And it uses an AOL (Append Only Log) to persist data.
In Part 1, I introduced Redis’ persistency layers:
Append-only log (AOL)
Redis database (RDB)
The advantages and disadvantages are:
AOL contains everything. It’s the most stable persistent model where data loss is almost impossible. Whenever you execute a command it is appended to the log. With Redis, it can be configured, and the default behavior is that it writes to the log file once a second. But it can changed to “write after every command.”
With RDB you can have data losses since it only persists to the file after X seconds (such as 60). However, the RDB file is usually smaller, and restoring the database from it is usually faster compared to AOL.
Now, let’s implement RDB. It stands for Redis Database. It’s a snapshot of your current dataset. Anything in the memory will eventually persist on the disk after a certain amount of time or number of operations. In this example, I’m going to persist the store after every X command.
If you want to try out the end product you can download the binaries here. Check out the project’s README. If there’s a problem you can build your own binaries with make build
Persisting data
Persisting the memory to the disk is quite simple. All we need to do:
Get every key from the
storeGet the nodes from the given key
Write them to a file
This file is going to be used when starting the server to restore the whole database. So it should store the data in a format that is optimized for one use case: reading the whole. As we have seen in the previous part, the best structure for this is to store everything line by line. Each line contains the data associated with one key. For example, if the server has the following keys in memory:
key: product-categories; values: [10 8 12 7 9 15]
key: customers; values: [129 113 148]
Then the file should look like this:
product-categories;binary_search_tree;10,8,12,7,9,15
customers;binary_search_tree;129,113,148It’s important to note that this structure only works with binary trees where each node has only two children.
As I said in a previous post, I use breadth-first traversal to get the tree. The first tree looks like this:
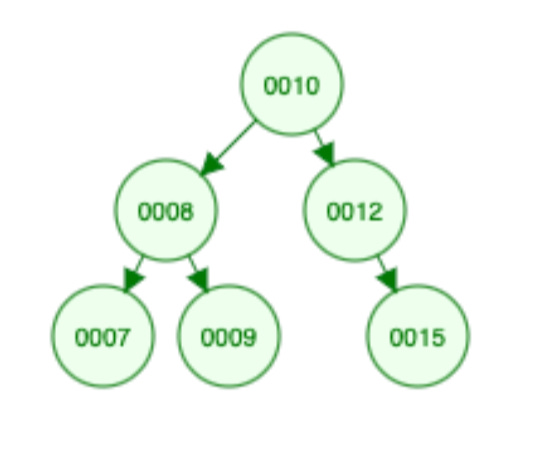
It’s pretty easy to reconstruct this free from the array [10 8 12 7 9 15].
If the project needs to handle n-ary trees (where each node can have N children) we would need to use a more sophisticated format. For example, an adjacency list for a 3-ary tree:
1:2,3,4
2:5,6,7
3:8,9,#
4:#,#,#
5:#,#,#
6:#,#,#
7:#,#,#
8:#,#,#
9:#,#,#1 has three children (2,3,4). 2 has three children (5,6,7). 3 has two children (8,9). # means the given node is null.
Given the fact that we only have a binary search tree at the moment, we can store it like this:
func persistTree(tree model.Tree, file *os.File) error {
values := tree.GetAll()
writer := bufio.NewWriter(file)
_, err := writer.WriteString(
fmt.Sprintf(
"%s;%s;%s",
tree.GetKey(),
tree.GetType(),
utils.IntArgsSliceToString(values),
),
)
if err != nil {
return err
}
err = writer.Flush()
if err != nil {
return err
}
return nil
}The function accepts a model.Tree which is an interface for all trees, and a file pointer. It retrieves all nodes from the tree and then writes a line to the file. The line looks like this:
product-categories;binary_search_tree;10,8,12,7,9,15It contains the key, the type, and the values separated by “,”
When we want to store a tree from memory to disk, we have the arguments as an integer array (slice). It needs to be converted into a string with delimiter characters. This is done by the utils.IntArgsSliceToString(values) function:
func IntArgsSliceToString(args []int64) string {
strArgs := make([]string, len(args))
for i, v := range args {
strArgs[i] = fmt.Sprint(v)
}
return strings.Join(strArgs, ",")
}The persistTree private function (because it starts with a lower-case letter) is called by the exported Persist function:
func Persist() error {
fmt.Println("RDB persisting to disk")
file, err := os.OpenFile(
fileName,
os.O_RDWR|os.O_CREATE|os.O_TRUNC,
0644,
)
if err != nil {
return err
}
for _, key := range store.Keys() {
tree, ok := store.Get(key)
if !ok {
continue
}
err = persistTree(tree, file)
if err != nil {
fmt.Println(err.Error())
}
}
err = file.Close()
if err != nil {
return err
}
return nil
}It opens the RDB file
It loops through every key found in the store (in the memory)
Then it gets the values associated with a given key
And calls the persistTree function described earlier
Basically, each key will have a line in the file.
There’s only one problem with that solution. bufio by default reads 4KB from a file (this is true for other languages as well, such as PHP or Java). But a tree can be of any size. Of course, we can fine-tune bufio to read a bigger chunk. For example, this will read 16KB:
bufferSize := 16 * 1024 // 16KB
reader := bufio.NewReaderSize(file, bufferSize)But trees can be much bigger than 16KB. The problem is that we don’t know the exact size. It can be 96KB or 72MB. Setting the buffer size to a huge value has two disadvantages:
First of all, it doesn’t guarantee that the line will fit into the buffer. It can always be just a byte bigger than your buffer size.
Even worse, if you have smaller lines you end up reading way too much data which makes your app really slow. In the worst-case scenario, you’ll end up reading the whole file each time.
Size does matter in this situation.
We didn’t have such a problem with AOL since every line contained a command that could not be too large. It’s something you type. In the worst case, it’s a few hundred characters.
Because of that, we need a smarter approach.
Fortunately, we can learn from relational database systems such as SQLite, MySQL, or PostgreSQL. By the way, in a future post, we’ll build a basic database storage engine.
Now, that was a smooth promotion, wasn’t it?
Keep reading with a 7-day free trial
Subscribe to Computer Science Simplified to keep reading this post and get 7 days of free access to the full post archives.