
Async workflows
Webscraping with Laravel jobs

Introduction
You probably already know what an async task means but here's a quick summary: asynchronicity means that a program can perform tasks independently of the main execution flow. In a typical Laravel app, it means we run background jobs while users can still interact with the application.
There's another concept that we don't usually use in PHP. It's called parallelism. It means simultaneous execution of multiple tasks, where each task is split into subtasks that can be processed concurrently.
Performance with Laravel
The following post is a chapter from my book, Performance with Laravel.
It discusses topics that help every web application to perform better:
Advanced Redis
Advanced database indexing
Designing performant and reliable architectures
CQRS
Async workflows
Optimizing jobs and workers
Concurrent programming
Working with large datasets
Export and imports
Decreasing memory consumption
fpm processes
nginx cache
Database optimization techniques
Much more
Use the coupon code “cssimplified“ to get a 30% discount for a limited time!

Web scraping
Web scraping is quite a good use case to demonstrate some interesting async workflows using jobs.
It's the process of extracting data from websites. It involves fetching the HTML content of a web page and then parsing the data to extract the desired information, such as text, images, links, or other content. This data can then be saved, analyzed, or used for various purposes.
I'd like to implement three features:
Discovering the available URLs on a website
Fetching the contents of these pages and extracting some information
Exporting everything to a CSV file
Usually, these kinds of scrapers are used to fetch some product and price information or simply to fetch e-mail addresses from websites and span the hell out of them. In this example, we'll build a simple one that discovers a site and then simply extracts H1 and H2 tags. It only handles that simple scenario and I only tested it with Freek's and my blog.
Here's how it works:
Fetch the given website's home page in HTML
Find every
<a>tag on the pageGo to that URL
Fetch
h1andh2tags and their contentRepeat
Step 2Export the results into a CSV
There's one major problem and it's Step 5. Can you guess why? Just think about it for a minute. Can you tell how many URLs a given website has before you start the scraping process?
You cannot, unfortunately. It's not like importing a huge CSV with 1,000,000 records. You know it has 1,000,000 rows and you can dispatch 1,000 jobs each processing 1,000 rows.
But if we don't know how many jobs we should start, how can we tell if every job has succeeded and we can start exporting the results?
On top of that, discovering URLs involves recursion which makes everything 10% more weird.
As far as I know, when you don't know how many jobs do you need you cannot determine if they succeded natively with Laravel's toolset.
We need two jobs:
DiscoverPageJobis the one with recursion. It fetches the content of a given URL and looks foratags. It dispatches anotherDiscoverPageJobfor every href it found.ScrapePageJobis the one that findsh1andh2tags and fetches their content.
There are a number of different approaches to running these jobs. Here's an example website that helps us understand these approaches:

The page /contact has no further links. Let's see two different solutions and compare them which would be faster.
Different approaches
Discover first
Discover every page and then dispatch the scrape jobs. This would look like this:
DiscoverPageJob('/')DiscoverPageJob('/blog')DiscoverPageJob('/blog/first-article')DiscoverPageJob('/blog/second-article')
DiscoverPageJob('/products')DiscoverPageJob('/products/first-product')DiscoverPageJob('/products/second-article')
DiscoverPageJob('/contact')
These jobs result in the URLs that the given website has. After that, we can dispatch 8 ScrapePageJobs for the 8 URLs.
Is this a good approach? To answer that question we need more information:
What does "good" mean? Good means two things in this example:
We want the scraping process to be as fast and effective as possible.
We have two runners and we don't want to have idle time when it's not necessary.
What are the other alternatives? Later we'll talk about them.
So there are two runners and we want to use them effectively. Let's simulate a scraping process:
We start with a DiscoverPageJob('/'). The two workers look like this:

In the next "tick" the job dispatches another job:

And now it discovers the last level:

This "branch" of the discovery process has ended. There are no other pages on the /blog branch. So it goes back to the /products branch:

And then goes to Level 3:

The branch has ended. It goes back to the last leaf of Level 2:

/contact does not have links so the discovery process has been completed.
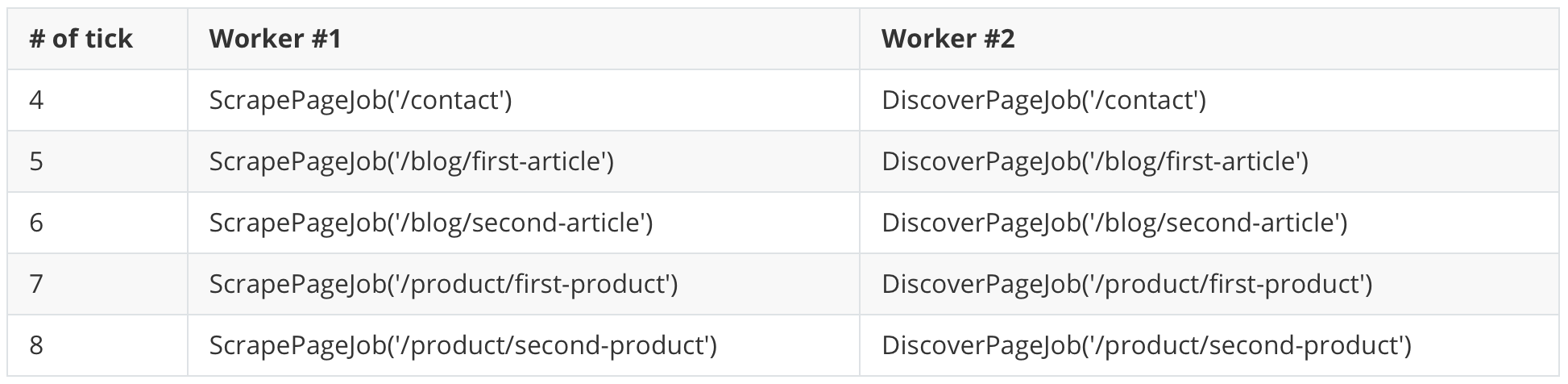
At this point, we have all 8 URLs so we can dispatch the 8 ScrapePageJob in 4 ticks. Both workers process one job at a time.
So it took 6 ticks to discover the website and then 4 ticks to scrape it. Overall it's 10 ticks.
Let's see the utilization of the workers:
In the discovery process Worker #2 was idle in 4 ticks. It was idle 4/6 or 67% of the time. That's probably not good.
Worker #1 was idle 0% of the time. Which is good.
Overall the two workers were utilized 8/12 or 67% of the time.
The scraping process utilizes both workers 100% which is perfect.
Number of ticks: 10
Overall utilization: 80.2% (weighted by number of ticks 6 vs 4)
Discover and scrape at the same time
This is the second approach. Discover one level of the website and scrape it immediately.
This is what it looks like:

You can immediately see the difference. As soon as we start discovering a page we can scrape it at the same time.
The DiscoverPageJob dispatches other Discover and also Scrape jobs. In the case of the home page, it finds three links: /blog, /products, and /contact so it dispatches 6 jobs to discover and scrape these 3 pages. This results in 6 pending jobs in the queue waiting to be processed.
The second tick:

Workers process the first jobs from the queue which is discovering and scraping the blog page. It has two links, so the discover job dispatches 4 new jobs.
The third tick:

This is the same but with the /products page. We know that there are no other links on the webpage so from here we can process everything.
And then the rest of the tick looks like this:
Here are the results:
Number of ticks: 8 (earlier it was 10)
Overall utilization: 100% (earlier it was 80.2%)
There's a 20% decrease in the number of ticks and a ~25% increase in utilization.
When I introduced the "Discover first" approach I asked the question, "Is this a good approach?" And then I gave you a bit more information:
What does "good" mean? Good means two things in this example:
We want the scraping process to be as fast and effective as possible.
We have two runners and we don't want to have idle time when it's not necessary.
What are the other alternatives? Later we'll talk about them.
Now we can clearly see it was not a "good" approach. At least not the best.
The next question: can we do better? And the answer is no because:
The sample website has 8 pages
It means 16 jobs (8 discover and 8 scrape)
With 2 workers 16 can be processed in 8 ticks with 100% utilization
So 8 ticks and 100% utilization is as good as it can be
The point is that if you want to make something async by using jobs try to think parallel. Try to squeeze as much work out of your workers as possible.
Performance with Laravel
The following post is a chapter from my book, Performance with Laravel.
It discusses topics that help every web application to perform better:
Advanced Redis
Advanced database indexing
Designing performant and reliable architectures
CQRS
Async workflows
Optimizing jobs and workers
Concurrent programming
Working with large datasets
Export and imports
Decreasing memory consumption
fpm processes
nginx cache
Database optimization techniques
Much more
Use the coupon code “cssimplified“ to get a 30% discount for a limited time!
Implementation
Let's start implementing the DiscoverPageJob:
class DiscoverPageJob implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels, Batchable;
public function __construct(
private Scraping $scraping,
private ?string $currentUrl = '',
private int $depth = 0,
private int $maxDepth = 3,
) {
if (!$this->currentUrl) {
$this->currentUrl = $this->scraping->url;
}
}
}First of all, let's talk about the arguments.
Scraping is a model that represents the scraping of a website. It has a HasMany relationship to the ScrapingItem model that contains every discovered URL on the site. This is the scrapings table:

I don't worry about user management and authentication right now but if it was a standard SaaS application the scraping table would have contained a user_id column.
scraping_items has records such as these:

A Scraping has many ScrapingItem. One for every URLs. The content contains the h1 and all the h2 tags on the given page.
Before we start a scraping process and dispatch the DicoverPageJob we have to create a Scraping model and pass it to the job.
The second parameter to the job is the $currentUrl which is empty by default. It refers to the URL the job has to discover. On the first run is the homepage so it defaults to the Scraping model's url property.
$depth refers to the current level that is being discovered just as I showed you earlier. $maxDepth sets a limit where the job stops discovering the page. It's not necessary but it's a great way to avoid jobs running for multiple hours or days (just imagine discovering 100% of Amazon).
public function handle(): void
{
if ($this->depth > $this->maxDepth) {
return;
}
$response = Http::get($this->currentUrl)->body();
$html = new DOMDocument();
@$html->loadHTML($response);
}It fetches the content of the current URL and then it parses it as HTML using PHP's DOMDocument class.
Then we have to loop through the <a> tags scrape them and discover the further.
foreach ($html->getElementsByTagName('a') as $link) {
$href = $link->getAttribute('href');
if (Str::startsWith($href, '#')) {
continue;
}
// It's an external href
if (
Str::startsWith($href, 'http') &&
!Str::startsWith($href, $this->scraping->url)
) {
continue;
}
}The two if conditions filter out links such as:
#second-headergoogle.com
These are links we don't need to discover and scrape.
As the next step, we can dispatch the scrape and the discover jobs to the new page we just found at $href. However, links can be in two forms, absolute, and relative. Some <a> tags contain links such as https://example.com/page-1 while others have a relative URL such as /page-1. We need to handle this:
if (Str::startsWith($href, 'http')) {
$absoluteUrl = $href;
} else {
$absoluteUrl = $this->scraping->url . $href;
}The $absoluteUrl variable contains an absolute URL where we can send HTTP requests so it's time to dispatch the jobs:
ScrapePageJob::dispatch($this->scraping, $absoluteUrl, $this->depth);
DiscoverPageJob::dispatch(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
);ScrapePageJob fetches the content of the page while DiscoverPageJob discovers all links on the page and dispatches new jobs.
ScrapePageJob is really simple:
class ScrapePageJob implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels, Batchable;
public function __construct(
private Scraping $scraping,
private string $url,
private int $depth
) {}
public function handle(): void
{
$scrapingItem = ScrapingItem::create([
'scraping_id' => $this->scraping->id,
'url' => $this->url,
'status' => 'in-progress',
'depth' => $this->depth,
]);
try {
$response = Http::get($this->url)->body();
$doc = new DOMDocument();
@$doc->loadHTML($response);
$h1 = @$doc->getElementsByTagName('h1')->item(0)->nodeValue;
$h2s = collect(@$doc->getElementsByTagName('h2'))
->map(fn ($item) => $item->nodeValue)
->toArray();
$scrapingItem->status = 'done';
$scrapingItem->content = [
'h1' => $h1,
'h2s' => $h2s,
];
$scrapingItem->save();
} catch (Throwable $ex) {
$scrapingItem->status = 'failed';
$scrapingItem->save();
throw $ex;
}
}
}It uses the same DOMDocument class to find h1 and h2 tags on the page and then it creates the scraping_items record. If something goes wrong it sets the status to failed.
So we have the main logic. We can discover and scrape webpages (all right, I didn't show 100% of the code here because it has some edge cases and small details but that's not important from the async point-of-view. You can check out the source code.)
Now look at this line again in the DiscoverPageJob:
ScrapePageJob::dispatch($this->scraping, $absoluteUrl, $this->depth);
DiscoverPageJob::dispatch(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
);How can we tell if scraping has finished? Right now there's no way. It's just an endless stream of jobs without any coordination.
Usually, when you want to execute a function or dispatch another job when a set of jobs has finished you can use job batches:
Bus::batch([
new FirstJob(),
new SecondJob(),
new ThirdJob(),
])
->then(function () {
echo 'All jobs have completed';
})
->dispatch();This is a really convenient way of waiting for jobs to be finished.
However, in our case, we don't know exactly how many jobs there are because the DiscoverPageJob recursively dispatches new ones.
So if we add a batch such as this:
foreach ($html->getElementsByTagName('a') as $link) {
$href = $link->getAttribute('href');
// ...
Bus::batch([
new ScrapePageJob($this->scraping, $absoluteUrl, $this->depth),
new DiscoverPageJob(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
),
])
->then(function () {
var_dump('Batch has finished');
})
->dispatch();
}The following happens:

In every loop, there's a batch with the jobs.
Another idea would be to create the batch before the loop, add the jobs to it inside, and then dispatch them once the loop is finished:
$batch = Bus::batch([]);
foreach ($html->getElementsByTagName('a') as $link) {
$href = $link->getAttribute('href');
// ...
$batch->add([
new ScrapePageJob($this->scraping, $absoluteUrl, $this->depth),
new DiscoverPageJob(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
),
]);
}
$batch
->then(function () {
var_dump('Batch has finished');
})
->dispatch();But it's not a good solution either. The only difference is that each batch has more jobs but we still have 8 batches if we're using the sample website from earlier as an example. Each DiscoverPageJob created a new batch with number of links * 2 jobs in it.
So using batches is the right path because they allow us to await jobs. However, as far as I know, our exact problem cannot be solved with Laravel's built-in methods and classes.
What we want to do is count the number of jobs as we dispatch them and then decrease the counter as workers process them.
First, I create a new function called dispatchJobBatch:
public function dispatchJobBatch(array $jobs)
{
Bus::batch($jobs)
->dispatch();
}This function is being used in the job's handle method:
$this->dispatchJobBatch([
new ScrapePageJob($this->scraping, $absoluteUrl, $this->depth),
new DiscoverPageJob(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
),
]);The next step is to implement the counter. Since we have multiple workers it has to be a "distributed" counter available to all workers. Redis and the Cache facade is an awesome starting point. I mean, the database cache_driver is equally amazing:
public function dispatchJobBatch(array $jobs, string $name)
{
$jobCountCacheKey = $this->scraping->id . '-counter';
if (Cache::has($jobCountCacheKey)) {
Cache::increment($jobCountCacheKey, count($jobs));
} else {
Cache::set($jobCountCacheKey, count($jobs));
}
Bus::batch($jobs)
->dispatch();
}I'm using the Scraping object's ID as part of the cache key and I increment it with the number of jobs being dispatched (usually 2).
So now we know exactly how many jobs are needed to scrape a given website:

Great! The next step is to decrease the counter as workers process the jobs. Fortunately, there's a progress method available on the Bus object:
Bus::batch($jobs)
->progress(function () {
var_dump("Just casually making some progress😎")
})
->dispatch();Now the output is this:

So the progress callback runs every time a job is processed in the batch. Exactly what we need:
public function dispatchJobBatch(array $jobs, string $name)
{
$jobCountCacheKey = $this->scraping->id . '-counter';
if (Cache::has($jobCountCacheKey)) {
Cache::increment($jobCountCacheKey, count($jobs));
} else {
Cache::set($jobCountCacheKey, count($jobs));
}
Bus::batch($jobs)
->progress(function () use ($jobCountCacheKey) {
Cache::decrement($jobCountCacheKey);
})
->dispatch()
}This is how it works:
Anytime you call this function and dispatch jobs the counter will be increased with the number of jobs
Then the batch is dispatched
After every job that has been completed the counter decreases
Now we're ready to add the then callback and run a callback when every job has been completed:
Bus::batch($jobs)
->then(function () use ($jobCountCacheKey, $scraping, $discoveredUrlsCacheKey) {
if (Cache::get($jobCountCacheKey) === 0) {
var_dump("Look! I'm ready 🥳");
}
})
->progress(function () use ($jobCountCacheKey) {
Cache::decrement($jobCountCacheKey);
})
->dispatch();The output is:

Exactly what we wanted! On the screenshot the var_dump is not the very last row, I know, but it's only the terminal output. Logically it works as it needs to.
Don't forget that we can only run our callback if the counter is zero. So this is a very important line:
if (Cache::get($jobCountCacheKey) === 0) {
var_dump("Look! I'm ready 🥳");
}Once again, the then function is called after a batch has been finished so we need this if statement.
One more thing we can do is delete the cache key entirely after all jobs have been completed:
->then(function () use ($jobCountCacheKey, $scraping, $discoveredUrlsCacheKey) {
if (Cache::get($jobCountCacheKey) === 0) {
Excel::store(new ScrapingExport($scraping), 'scraping.csv');
Cache::delete($jobCountCacheKey);
}
})And of course, instead of var_dumping I actually dispatch another export job but that's not important right now, and there's a dedicated chapter for exports and imports.
Here's the whole function:
public function dispatchJobBatch(array $jobs)
{
$jobCountCacheKey = $this->scraping->id . '-counter';
if (Cache::has($jobCountCacheKey)) {
Cache::increment($jobCountCacheKey, count($jobs));
} else {
Cache::set($jobCountCacheKey, count($jobs));
}
$scraping = $this->scraping;
Bus::batch($jobs)
->then(function () use ($jobCountCacheKey, $scraping, $discoveredUrlsCacheKey) {
if (Cache::get($jobCountCacheKey) === 0) {
Excel::store(new ScrapingExport($scraping), 'scraping.csv');
Cache::delete($jobCountCacheKey);
}
})
->progress(function () use ($jobCountCacheKey) {
Cache::decrement($jobCountCacheKey);
})
->dispatch();
}In these callbacks (then, progress, etc) we cannot use $this. This is why there's this line $scraping = $this->scraping and then the $scraping variable is being used in the then callback.
And this is what the handle method looks like:
public function handle(): void
{
if ($this->depth > $this->maxDepth) {
return;
}
$response = Http::get($this->currentUrl)->body();
$html = new DOMDocument();
@$html->loadHTML($response);
foreach ($html->getElementsByTagName('a') as $link) {
$href = $link->getAttribute('href');
if (Str::startsWith($href, '#')) {
continue;
}
// It's an external href
if (
Str::startsWith($href, 'http') &&
!Str::startsWith($href, $this->scraping->url)
) {
continue;
}
if (Str::startsWith($href, 'http')) {
$absoluteUrl = $href;
} else {
$absoluteUrl = $this->scraping->url . $href;
}
$this->dispatchJobBatch([
new ScrapePageJob($this->scraping, $absoluteUrl, $this->depth),
new DiscoverPageJob(
$this->scraping, $absoluteUrl, $this->depth + 1, $this->maxDepth
),
]);
}
}The main takeaways from this example:
Use async jobs whenever it's possible
Plan your workflow because there's a big difference between different solutions
Batches are great
Performance with Laravel
The following post is a chapter from my book, Performance with Laravel.
It discusses topics that help every web application to perform better:
Advanced Redis
Advanced database indexing
Designing performant and reliable architectures
CQRS
Async workflows
Optimizing jobs and workers
Concurrent programming
Working with large datasets
Export and imports
Decreasing memory consumption
fpm processes
nginx cache
Database optimization techniques
Much more
Use the coupon code “cssimplified“ to get a 30% discount for a limited time!